

You can read all the posts in this series here:
- Part 1. An Introduction to DeepFakes and Face-Swap Technology
- Part 2. The Ethics of Deepfakes
- Part 3. How To Install FakeApp
- Part 4. A Practical Tutorial for FakeApp
- Part 5. An Introduction to Neural Networks and Autoencoders
- Part 6. Understanding the Technology Behind DeepFakes
- Part 7. How To Create The Perfect DeepFakes
If you are interested in reading more about AI Art (Stable Diffusion, Midjourney, etc) you can check this article instead: The Rise of AI Art.
In the previous part of this series, An Introduction to Neural Networks and Autoencoders, we have explained the concept of autoencoding, and how neural networks can use it to compress and decompress images.
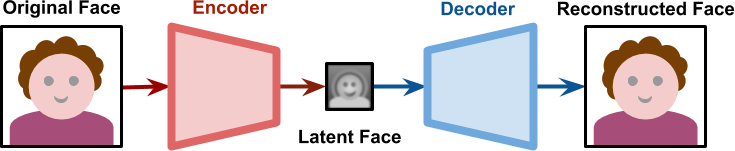
The diagram above shows an image (in this specific case, a face) being fed to an encoder. Its result is a lower dimensional representation of that very same face, which is sometimes referred to as base vector or latent face. Depending on the network architecture, the latent face might not look like a face at all. When passed through a decoder, the latent face is then reconstructed. Autoencoders are lossy, hence the reconstructed face is unlikely to have the same level of detail that was originally present.
The programmer has full control over the shape of the network: how many layers, how many nodes per layer and how they are connected. The real knowledge of the network is stored in the edges which connect nodes. Each edge has a weight, and finding the right set of weights that make the autoencoder works like described is a time-consuming process.
Training a neural network means optimising its weights to achieve a specific goal. In the case of a traditional autoencoder, the performance of a network is measured on how well it reconstructs the original image from its representation in latent space.
Training Deepfakes
It is important to notice that if we train two autoencoders separately, they will be incompatible with each other. The latent faces are based on specific features that each network has deemed meaningful during its training process. But if two autoencoders are trained separately on different faces, their latent spaces will represent different features.
What makes face swapping technology possible is finding a way to force both latent faces to be encoded on the same features. Deepfakes solved this by having both networks sharing the same encoder, yet using two different decoders.
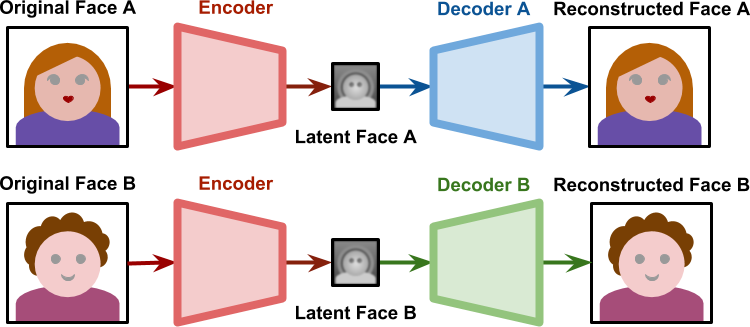
During the training phase, these two networks are treated separately. The Decoder A is only trained with faces of A; the Decoder B is only trained with faces of B. However, all latent faces are produced by the same Encoder. This means that the encoder itself has to identify common features in both faces. Because all faces share a similar structure, it is not unreasonable to expect the encoder to learn the concept of “face” itself.
Generating Deepfakes
When the training process is complete, we can pass a latent face generated from Subject A to the Decoder B. As seen in the diagram below, the Decoder B will try to reconstruct Subject B, from the information relative to Subject A.

If the network has generalised well enough what makes a face, the latent space will represent facial expressions and orientations. This means generating a face for Subject B with the same expression and orientation of Subject A.
To better understand what this means, you can have a look at the animation below. On the left, faces of UI Artist Anisa Sanusi are extracted from a video (link) and aligned. On the right, a trained neural network is reconstructing the face of game designer Henry Hoffman to match Anisa’s expression.

It should be obvious, at this point, that the technology behind deep fakes is not constrained on faces. It can be used, for instance, to turn apples into kiwis.

What is important is that the two subjects used in the training share as many similarities as possible. This is to ensure that the shared encoder can generalise meaningful features that are easy to transfer. While this technique will work on both faces and fruits, is unlikely to convert faces into fruits.
Conclusion
You can read all the posts in this series here:
- Part 1. An Introduction to DeepFakes and Face-Swap Technology
- Part 2. The Ethics of Deepfakes
- Part 3. How To Install FakeApp
- Part 4. A Practical Tutorial for FakeApp
- Part 5. An Introduction to Neural Networks and Autoencoders
- Part 6. Understanding the Technology Behind DeepFakes
- Part 7. How To Create The Perfect DeepFakes
💖 Support this blog
This website exists thanks to the contribution of patrons on Patreon. If you think these posts have either helped or inspired you, please consider supporting this blog.
📧 Stay updated
You will be notified when a new tutorial is released!
📝 Licensing
You are free to use, adapt and build upon this tutorial for your own projects (even commercially) as long as you credit me.
You are not allowed to redistribute the content of this tutorial on other platforms, especially the parts that are only available on Patreon.
If the knowledge you have gained had a significant impact on your project, a mention in the credit would be very appreciated. ❤️🧔🏻
This is fascinating. I wonder if this could be applied to other objects within a video. Take for example of two national flags, blowing in the breeze. provided they have similar lighting and overall shape, could we change an Australian Flag into a US flag?
Definitely!
FakeApp is based on an autoencoder that could, potentially, learn any mapping.
I have a picture, further on, where I am swapping apples with kiwis.
The only problem is that if you want to do that on a video, you’ll need to find the position of the apple first.
There are a lot of face detection algorithms, but not so many for apples and flags! 😀
This is interesting. It would be fun to see if it’s possible to generate human faces from animal faces, like what animal do you look like and other similar applications.
The reason why DeepFakes work is because when two faces are compressed into latent faces, the network is forced to identify similarities. Faces have a very similar structure, but the same might not happen for animals. I’d be happy to see it implemented though!
Do you have access to the training data for apples and kiwis? Is there any way I could download this model?
Hi Andrew!
No, I did not make that dataset public as it was not the best.
I got a 3D model of a wiki and an apple.
And simply used Unity to render images of them at different angles.
Excelent post! One question, what are good resources to see the mathematical formulation of Deepfakes, in specific, how is the traininng process in the NN in Fig. 2 and 3. Thanks in Advance.
Hi Alan! Thanks for your very informative blog posts. I just wanted to let you know that I actually cited your blog and used your info graphics in my Law Review note addressing some First Amendment concerns with regulating deepfakes. You can find the article here: https://scholarlycommons.law.case.edu/cgi/viewcontent.cgi?article=4854&context=caselrev
I just wanted to let you know and say thanks!
Thank you so much for letting me know, Jessica!
I hope this article has helped you!
the best explanation of deepfakes I have found to date
Thank you!
I have a plan to make an updated series since so much has changed in the past few years!
Please tell me how to remove that message which shows on the screen after installing the software.
Can I find the code that uses same encoder, but different decoders