

This series of tutorial is about evolutionary computation: what it is, how it works and how to implement it in your projects and games. At the end of this series you’ll be able to harness the power of evolution to find the solution to problems you have no idea how to solve. As a toy example, this tutorial will show how evolutionary computation can be used to teach a simple creature to walk. If you want to try the power of evolutionary computation directly in your browser, try Genetic Algorithm Walkers.

- Introduction
- Part 1.
NaturalArtificial Selection - Part 2. Phenotype and Genotype
- Part 3. Evolutionary Programming
- Part 4. Local Maxima
- Conclusion
Introduction
As a programmer, you might be familiar with the concept of algorithm. When you have a problem, you write a precise set of instructions to solve it. But what happens when the problem is too complex, or you have no idea how to solve it? While there’s a very precise strategy to optimally play Sudoku, this is not the case for face recognition. How can we code the solution to a problem, when we have no idea how solve it in the first place?
This is a typical scenario in which artificial intelligence finds a real application. One of the easiest techniques that can be used to solve this class of problems is evolutionary computation. In a nutshell, it is based on the idea of applying Darwinian evolution to a computer program. The aim of evolution is to improve the quality of an poor solution, by randomly mutating it until it solves the problem with the necessary accuracy. In this tutorial we will explore how evolutionary computation can be applied to learn an optimal walking strategy. You can see a more advanced work in the video below (article: Flexible Muscle-Based Locomotion for Bipedal Creatures).
Natural Artificial selection
Chances are you have heard of Darwin’s concept of the survival of the fittest. The basic idea is simple: surviving is a hard task, and the creatures who can do it have a higher chance of reproducing. The environment naturally selects the creatures who best fit it, killing the ones that fail in such a task. This is often shown in the over simplified (and highly misleading) example of the giraffes: a longer neck helped giraffes to reach higher branches. Over time, this supposedly selected giraffes with longer and longer necks. There has never been a direct force to “extend” the neck of giraffes. Over time, the ones with naturally longer necks have been favourited by the environment.
The same mechanism can be applied to computer programs. If we have an approximate solution to a problem, we can randomly alter it and test whether the change we have made improves (or not) its performance. If we keep iterating this process, we always end up with a better (or equal) solution. Natural selections is truly agnostic to the problem; at its core, it’s driven by random mutations.
Phenotype and Genotype
In order to understand how computing meets evolution, we need to understand the role of evolution in biology first. In nature, every creature has a body and a set of behaviours. They are know as its phenotype, which is the way a creature appears and behave. Hair, eyes and skin colour are all part of your phenotype. The look of a creature is mostly determined by a set of instructions written in its own cells. This is called genotype, and it refers to the information that is carried out, mostly in our DNA. While the phenotype is how a house looks like once its built, the genotype is the original blueprint that drove its construction. The first reason why we keep phenotype and genotype separate is simple: the environment plays a huge role in the final look of a creature. The same house, built with a different budget, could look very different.
The environment is, in most cases, what determines the success of a genotype. In biological terms, surviving long enough is succeeding. Successful creatures have a higher chance of reproducing, transmitting their genotype to their offspring. The information to design the body and the behaviours of each creature is store in its DNA. Every time a creature reproduces, its DNA is copied and transmitted to its offspring. Random mutations can occur during the duplication process, introducing changes in the DNA. These changes can potentially result in phenotypical changes.
Evolutionary Programming
Evolutionary computation is rather broad and vague umbrella term that groups together many different – yet similar – techniques. To be more specific, we will focus on evolutionary programming: the algorithm we are iterating over is fixed, but its parameters are open to optimisation. In biological terms, we are only using a natural selection on the brain of our creature, not on its body.
Evolutionary programming works simply replicating the mechanism of natural selection:

- Initialisation. Evolution requires to be seeded with an initial solution. Choosing a good starting point is essential, since they might lead to totally different results.
- Duplication. Many copies of the current solution are made.
- Mutation. Each copy is randomly mutated. The extent of the mutation is critical, as it controls the speed at which the evolutionary process run.
- Evaluation. The score of a gene is measured depending on the performance of the creature that has generated. In many cases this requires an intensive simulation step.
- Selection. Once creatures have been evaluated, only the best ones are allowed to be duplicated to seed the next generation.
- Output. Evolution is an iterative process; at any point it can be stopped to obtain an improved (or unaltered) version of the previous generation.
Local maxima
What evolution does, it trying to maximise the fitness of a genome, to better fit a certain environment. Despite being deeply connected to Biology, this can be seen purely as an optimisation problem. We have a fitness function, and we want to find its maximum point. The problem is that we don’t know how the function looks like, and we can only make a guess by sampling (simulating) the points around our current solution.

The diagram above shows how different mutations (on the X axis) leads to different fitness scores (Y axis). What evolution does is sampling random points in the local neighbourhood of  , trying to increase the fitness. Given the size of the neighbourhood, many generations are necessary to reach the maximum. And this is where it gets complicated. If the neighbourhood is too small, evolution can get stuck in a local maxima. They are solutions that are locally optimal, but not globally. It is very common to find local maxima in the middle of fitness valleys. When this happens, evolution might be unable to find a better nearby solution, getting stuck. It is often said that cockroaches are stuck in an evolutionary local maxima (Can An Animal Stop Evolving?): they are extremely successful at what they do, and any long-term improvement requires a too high short-term penalty on their fitness.
, trying to increase the fitness. Given the size of the neighbourhood, many generations are necessary to reach the maximum. And this is where it gets complicated. If the neighbourhood is too small, evolution can get stuck in a local maxima. They are solutions that are locally optimal, but not globally. It is very common to find local maxima in the middle of fitness valleys. When this happens, evolution might be unable to find a better nearby solution, getting stuck. It is often said that cockroaches are stuck in an evolutionary local maxima (Can An Animal Stop Evolving?): they are extremely successful at what they do, and any long-term improvement requires a too high short-term penalty on their fitness.
Conclusion
This post introduced the concept of evolution, and the role it plays in Artificial Intelligence and Machine Learning.
The next post will start the actual tutorial on how to implement evolutionary computation. Designing the body of a creature that can be evolved is the first necessary step.
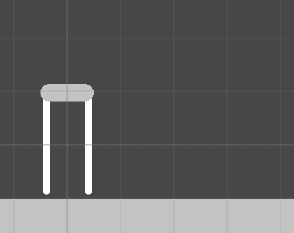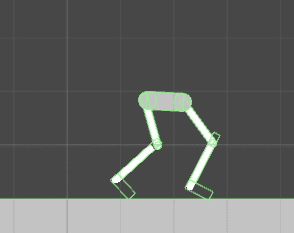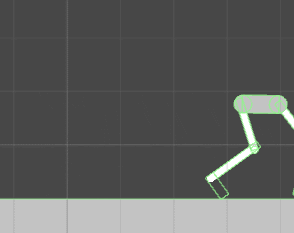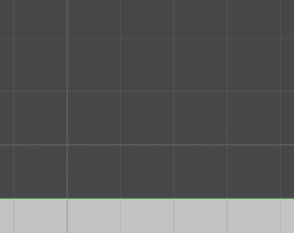
Other resources
- Part 1. Evolutionary Computation: Theory
- Part 2. Evolutionary Computation: Phenotype
- Part 3. Evolutionary Computation: Genotype
- Part 4. Evolutionary Computation: Loop
💖 Support this blog
This website exists thanks to the contribution of patrons on Patreon. If you think these posts have either helped or inspired you, please consider supporting this blog.
📧 Stay updated
You will be notified when a new tutorial is released!
📝 Licensing
You are free to use, adapt and build upon this tutorial for your own projects (even commercially) as long as you credit me.
You are not allowed to redistribute the content of this tutorial on other platforms, especially the parts that are only available on Patreon.
If the knowledge you have gained had a significant impact on your project, a mention in the credit would be very appreciated. ❤️🧔🏻
Very well interesting & well written! But I have a question about the end, and maximizing our fitness w.r.t. the neighborhood. You say it’s complicated to pick a neighborhood size, and explain why too-small can be dangerous… so then the neighborhood should just be as big as possible?
I assume there are also some downsides with too-big a neighborhood (presumably would take a much longer time to reach even a local maxima, let alone the global), but perhaps you could address that in a comment or addendum? 🙂
Hey! Part 2 and Part 4 will address most of these issues.
You can imagine the size of the neighbourhood as the speed of a car that tries to park. If you go too slow, you won’t reach the parking lot. If you’re too fast, you’ll miss it. The speed is essential to get exactly right where you want. Ideally, you want decelerate as you get close. This is exactly what a good algorithm should do. When this is the case, we’re talking about gradient descent. This tutorial won’t really cover it. It will simply make random changes, regardless how “close” we are to the best solution.
Will an example Unity scene with the walker prefab be available for download or is only sample C# code available?
(To avoid confusing people reading this, I have early access to the whole tutorial) Update: I made a dancing, wiggling table that responds to changes in the genome. Now to implement all the other things…
Hey!
Yes, a proper Unity package in C# will be provided!
I think I’ll release it probably with the latest tutorial, so I can have more time to clean up the project and make it more flexible for other applications! 😀
Just finished a simple execution of this. Still have a ways to go to make it great but it has really been a fascinating learning experience. Great article.
Awesome! 😀 Feel free to share your results! I’d be happy to see what you’ve been up to! 😀
My implementation is ultra basic right now but it’s been really fun getting it going. Currently I have two creatures “on stage” with four seconds to perform, best one stays and the other gets the genes of the winner, both mutate, repeat. Screenshot: http://imgur.com/S8AUjDX
Ohhh sweet! 😀
I am building more complex creatures. The problem is that Unity’s physics is not helping me in having results that can be reproduced easily. T_T