

In the last few months the Internet has been flooded with deep dreams: images augmented by neural networks which look incredibly trippy. Deep dreams have the potential to become the new fractals; beautifully backgrounds everyone knows are related to Maths, but no one knows really how. What are deep dreams, how are they generated and what can they teach us?
The Theory
A neural network gets an image as an input, and returns a classification result: yes, that’s a face. It achieves this by recognising features in an hierarchical fashion. The first neurons which access the image directly are generally sensitive to very simple features such as particular colours, edges and orientations. Then next layer of neuron takes inputs from the previous one, and builds higher level features. Pieces of objects are typically recognised at this level: door knobs, handles, table legs, etc. By keep adding a layer on top of the previous one the neural network can develop more and more complex features, until it eventually recognises the difference between a cat and a human face. This process of hierarchical feature extraction is shown very well in the following diagram.
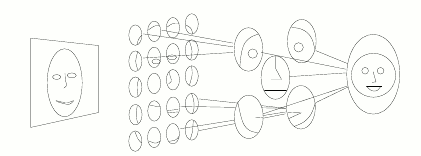
For many years it has been believed neural networks should only have three layers. Recent studies shown how networks with several more layers (called deep networks) are much more effective. The types of networks we’re interested in are often referred as Large Scale Deep Neural Networks, but let’s be honest that’s just a cheeky way so you can call them LSD-NN.
The Training
There are two challenging parts when it comes to creating a neural network. The first is how to design the network itself. The second is how to train it so that each neuron knowns which features of the previous layers are important for him. While the first challenge is still open, researchers have very efficient methods to train neural networks. The most common way is to provide the network with millions of classified images. Every time the network misclassifies an image, neurons are adjusted accordingly to compensate until the entire network reaches a certain threshold of accuracy. This process is called back propagation and, surprisingly, very little is known about how (and why) neurons naturally start recognising features. These features are not encoded by researchers, but they emerge as a result of the training process.
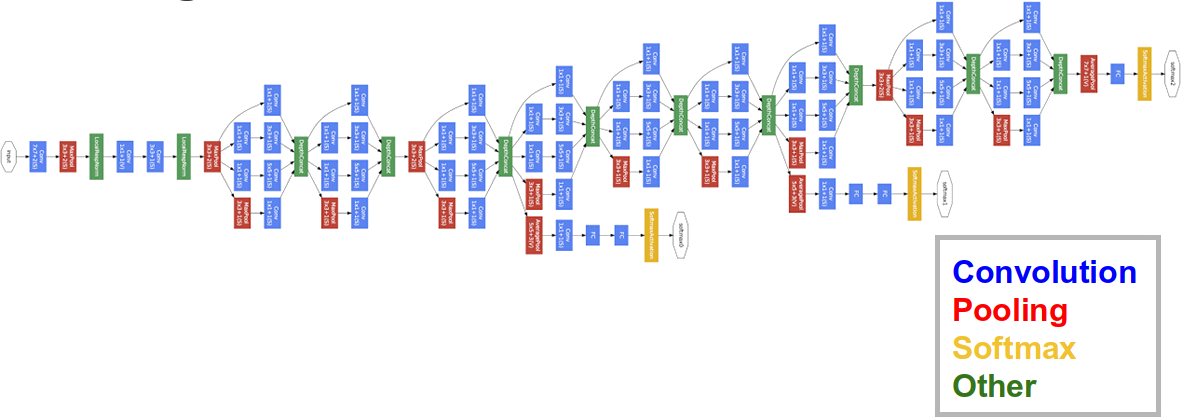
This diagram shows GoogLeNet, the neural network developed by Google Research. Each box is a different layer, typically containing thousands of neurons each.
Reversing Neural Networks
To understand how neural networks learn, is necessary to understand how features are recognised in the first place. If we analyse the output a particular neuron, we can see that it activates strongly when it detects a certain pattern. The higher the layer, the more complicate this pattern can be, up to the point were certain neurons are de fact responding only to certain objects. When we want to analyse a neuron, it’s not very practical to feed him with images until we understand what it detects. A better approach is to reverse the way the network works. Instead of providing an image and asking what it is, we can pick a neuron and ask it which image would stimulate it the most. By propagating this information back in the network, each neuron will draw on the image the pattern (or the object) it wants to see.

In this example, a layer highlights a patterns in the image. This indicates this layer is sensitive to certain strokes, and tries to add as many as possible to the image.
Dreams and hallucinations
The process of investigating a neuron’s response forces the network to imagine something which is not there. Terms such as dreams and hallucinations have often been used. Despite not being related at all with actual dreams and hallucinations, they’ve captured the media attention. Dreams are actually very important because they highlight what the network has learnt. Alexander Mordvintsev has shown how a network trained to recognise dumbbells only generates dumbbells which are hold by a human arm. That’s a clear indication the network has failed to understand what a dumbbell really is, perhaps because it has always been shown pictures of people holding them.

Inceptionism

The team at Google Research has explored this technique of probing neural networks even further, with what they called inceptionism. Given an image, the layer we want to investigate is asked how’s the image should be changed to make it more active. If the layer detects dogs and is provided with a human face, it will morph it slowly into what it believes is a dog. Since neural networks are incredibly robust to scaling, rotation and translation, they can see dog faces at different scales. This is where the term inceptionism comes from: dogs within dogs within dogs within dogs…
Conclusion
This post briefly introduces neural networks and how they work, at a high level of abstraction, to classify images. To understand which neurons are responsible for which features, researchers have developed several techniques: deep dreaming is one of them.
The next part of this tutorial will teach you how to run the code necessary to generate and customise deep dreams.
Other resources
- Part 1. Understanding Deep Dreams
- Part 2. Generating Deep Dreams
- Going Deeper with Convolutions: the original paper from Google Research which discuss how they have implemented neural networks to classify images very effectively;
- Inceptionism: Going Deeper into Neural Networks: a follow up blog post on the above mentioned article;
- Deep learning: a website with lot of updated resources on deep learning;
- 317070: this Twitch channel is constantly streaming an interactive deep dream;
- LSD Neural Net: the description of how 317070 works.
💖 Support this blog
This website exists thanks to the contribution of patrons on Patreon. If you think these posts have either helped or inspired you, please consider supporting this blog.
📧 Stay updated
You will be notified when a new tutorial is released!
📝 Licensing
You are free to use, adapt and build upon this tutorial for your own projects (even commercially) as long as you credit me.
You are not allowed to redistribute the content of this tutorial on other platforms, especially the parts that are only available on Patreon.
If the knowledge you have gained had a significant impact on your project, a mention in the credit would be very appreciated. ❤️🧔🏻
Like the old phrase say “To a carpenter everything is a nail.”
Has google tried to unteach such a neural net to see if it starts seeing images for what they are?
You mean “To a Carpenter with a Hammer, Every Problem Looks Like a Nail”
Yes, thanks.
Interesting to read. Thanks for another great article!
Hi!
Here is the link to my new tutorial on deepdream, this time with TensorFlow: https://github.com/tensorflow/tensorflow/tree/master/tensorflow/examples/tutorials/deepdream
Best viewed with nvbiewer http://nbviewer.jupyter.org/github/tensorflow/tensorflow/blob/master/tensorflow/examples/tutorials/deepdream/deepdream.ipynb