

This article is about an interesting, yet forgotten sorting algorithm: the Sunrise sort. It is possibly the only one to have a rather unusual property: it is fully unstable.
Sorting has been a recurring theme on this blog, from The Incredibly Challenging Task of Sorting Colours to GPU Sorting (animation below). If sorting algorithms—especially the more “esoteric” ones—are a subject that easily captures your imagination, this is an article you definitely want to read.
And for the ones who will dare to stay till the end, you will discover what made the Sunrise sort a “forgotten” algorithm.
An Introduction to Sorting Algorithms
Imagine you have a list of documents, and you want to sort them by date. How would you do it? Which strategy would you use? And how would you implement an algorithm to do it automatically? This is what Computer Scientists call a sorting algorithm.
Sorting is, by itself, an interesting problem. But there are not that many scenarios in which you only need to sort a list. Instead, sorting is often a necessary gear for other, more complex problems. Many data structures, for instance, can achieve very good performance on collections that are sorted. It is the case of the binary search, which allows finding an object in a list in  steps, compared to the much more inefficient linear search which has a complexity of
steps, compared to the much more inefficient linear search which has a complexity of  .
.
In this section we have used the so-called Big O notation (also known as the Bachmann–Landau notation). This is a Mathematical notation adopted by Computer Scientists to talk about the efficiency of an algorithm. More specifically, to talk about how long an algorithm takes, as a function of its input size.
The Big O notation has the advantage of giving a simple, easy-to-compare way to measure computational complexity. For the purpose of this article, you only need to understand two notations:
 : the algorithm takes at most
: the algorithm takes at most  steps to complete;
steps to complete; : the algorithm takes exactly steps to complete;
: the algorithm takes exactly steps to complete;
where  is the size of the input.
is the size of the input.
For instance, binary search has a complexity of , which means it will take at most  iterations (on a list of elements) before terminating.
iterations (on a list of elements) before terminating.
One advantage of the Big O notation is that does not necessarily have to be the exact function, but it indicate to “order of magnitude”.
It is not unsurprising that sorting algorithms play a fundamental role in Computer Science. So fundamental that the French word for “computer” is “ordinateur“, which actually means “sorter”. Yet, many have developed an unhealthy obsession for them, which is probably only comparable to the obsession and respect that mathematicians hold for prime numbers.
It is also worth noticing that an entire “zoo” of sorting algorithms exists. One that is only bound to get bigger, given that there are potentially infinitely many different strategies to sort the elements of a list. And while each one does it in a slightly different way (perhaps even under slightly different constraints), most of them find no application in modern computer science. Besides being taught in academia as a necessary step towards the few ones which are actually used, of course!
Quick sort, merge sort and—to some lesser extent—insertion sort, have been the most influential ones in modern software engineering. Other ones may find useful applications in contexts which lack the flexibility of random access memory, or which can make use of highly parallelised architectures.
❓ Which sorting algorithms are used by modern frameworks?Because each sorting algorithm has its own pros and cons, most modern languages and frameworks are relying on “mixed” solutions. Both C# and Java, for instance, change which sorting algorithm to use based on the size of the collection. And they both use hybrid variants (such as the Trimsort and the Dual Pivot Quick Sort) which rely on different techniques.
Below, a few tables showing which sorting algorithms have been historically used by modern frameworks and languages:
| Collection types |  |  |
Java  | Insertion sort | Merge sort |
Java  | Insertion sort | Trimsort |
| Primitive types |  |  |
| Java | Insertion sort | Dual Pivot Quick Sort |
C# .NET  | Quicksort |
 | default | partitions  | |
C# .NET  | Insertion sort | Quicksort | Heap sort |
- Dual pivot quicksort: a combination of insertion sort and quick sort (source);
- Trimsort: a combination of insertion sort and merge sort (specifically designed for python);
- Introsort (introspective sort): quicksort as a default, switching to heapsort when recursion is too deep or insertion sort when the collection size is below a certain threshold (it is the one currently used by .NET: source).
Sorting stability
The Sunrise sort is a sorting algorithm with a rather unique property: it is fully unstable. But to understand what that means, we need to understand what stability is in this context.
When talking about sorting algorithm, stability is a property that is often desired. A sorting algorithm is stable if it preserves the relative order of any repeated elements in the list. If we are sorting primitive types (such as numbers), stability is not an issue. But it is common to sort complex data structures based on a key. For instance, let’s imagine that we are sorting a list of people using their names are keys: what happens if two entries share the same name? From a purely utilitarian perspective, it does not matter which one comes first. But a stable sorting algorithm will ensure that their order in which they appear in the unsorted list is preserved. This means that if there are two people with the same name (let’s refer to them as Person 1 and Person 2), and Person 1 comes before Person 2 in the unsorted list, then a stable sorting algorithm will sort Person 1 before Person 2.

Many algorithm are stable “by nature”, meaning that the way in which they operate naturally preserves the relative order of the elements. The Bubble sort, Insertion sort and Merge sort falls into this category. Others, such as the Quick sort and Heap sort are unstable when implemented naively.
Most sorting algorithms can be modified to be stable, simply by changing the comparison operator so that it can take into account the position of the items in the original list. This, however, can compromise their performance. This is particularly true for ones which operates on the original list, since they may need to store the relative position of the elements somewhere else.
It is important to notice that an unstable algorithm makes no guarantee about preserving (or not) the relative order of the elements it sorts. It may very well be that you run Quick sort on a list, and that the relative order is indeed preserved. Or it may preserve it, but only sometimes. Stability is a guarantee of a property; instability is the lack of that guarantee, which is very different from the guarantee of instability.
And this is where the Sunrise sort comes into play. It is the only sorting algorithm designed to be fully unstable. This is a property which ensures that repeated elements are shuffled every time the algorithm runs. Because stability is often desired, it might sound weird to have an algorithm which is intentionally non-stable. And indeed, its full instability makes the Sunrise sort an unlikely candidate for most applications. However, it is exactly that property that can come in very handy in a variety of real-life scenarios.
The Sunrise sort is in fact useful when we want to generate a random permutation of a priority list. When invoked on a non-decreasing collection, it will in fact permutate the orders of all repeating items. A typical applications for this could be a list of tasks, which needs to be shuffled, but sorted based on their priority class (“low”, “medium”, “high”).
❓ Is there an alternative way to achieve this?Yes! The same effect could be achieved by reshuffling the array first, and sorting it with stable algorithm after. This would naturally preserved the random placement of the repeated elements.
Because shuffling has a linear complexity ( ), its computational cost is absorbed by the linearithmic complexity of the sorting step (
), its computational cost is absorbed by the linearithmic complexity of the sorting step ( ). This means that shuffling a collection before sorting it does not alter its overall time complexity. However, it still has an impact on the performance. The Sunrise sort, on the other hand, performs both these operations efficiently.
). This means that shuffling a collection before sorting it does not alter its overall time complexity. However, it still has an impact on the performance. The Sunrise sort, on the other hand, performs both these operations efficiently.
To be very precise, the Sunrise sort is not the only algorithm which is fully unstable. The Bogosort also has that property. If you are unfamiliar with it, is because the Bogosort is a ridiculously inefficient algorithm, designed to be intentionally inefficient.
It works by randomly reshuffling items, until they happen to be sorted:
public void Bogosort (T[] array)
{
while (! IsSorted(array))
Shuffle(array);
}
One drawback of this technique is that, if implemented as above, it does not cause elements to be reshuffled on an array that is already sorted. Which actually makes it stable, on an already sorted array.
The Merge Sort
In order to understand how the Sunrise sort works, we need first to talk about the Merge sort first. This is because the Sunrise sort is a variant of the Merge sort.
Conceptually, the merge sort is very simple, and works in two phases:
- Split phase: the collection is recursively split in two halves, until a single element is reached;
- Merge phase: two sub-collections are merged back and sorted at the same time.

There are two ideas behind the Merge sort. The first one is that while it is complicated to sort a list, it is pretty straightforward to merge two lists that are already sorted. The second idea is that a collection of a single element is already sorted. This is why the Merge sort first splits the collection into halves, until it reaches individual elements. At this stage, each one-element collection is sorted. Then, they can be recursively merged back.
The stability of the Merge sort comes from the fact that is only performs swaps when strictly necessary. Hence, if two elements are already sorted, they will not be swapped.
The Sunrise Sort
The Sunrise sort was originally developed in 2007 at the University of Pisa, as part of the Doriana82 project. What sets it apart from the Merge sort, is its ability to reshuffle elements during the merge phase. This is done through the introduction of a new concept: blocks. In the context of the Sunrise sort, a block is a group of nearby elements which all have the same value. During the merge phase, the Sunrise sort keeps track of each block, and ensures that when an element is merged into one, it is placed randomly inside it.
The concept of blocks really makes sense only if the list has many repeated elements. If we could give a colour to each item, instead of a smooth gradient we likely get a more “stratified” transition. Exactly what you see in a Tequila Sunrise. There is no lack of food analogies in sorting algorithms. From pancake sort to the spaghetti sort, even going as far as naming one of them cocktail shaker sort and—to some lesser extent—even the Bubble sort. So it felt fitting to add another food-related sorting algorithm to the list.

When the Sunrise sort is sorting elements in decreasing order, it is also called the Sunset sort.
👥 The Doriana82 projectDoriana82 was an Italian chatbot developer for the now defunct Live Messenger. Available at chattami@doriana82.it, she was born as a parody of Doretta82, the overly sexualised chatbot created by Microsoft itself to promote their search engine. Over the course of a couple of years, Doriana82 survived the shutdown of her competitor, eventually becoming the most popular Italian chatbot on Live Messenger.
This was thanks to the fact that she could learn new words and phrases from her many users, making her progressively more unhinged. Although unrelated, Doriana82 was somewhat of a precursor to later chatbots such as the unfortunately Tay, minus the racism. Together with my collaborator, Francesco Orsi, Doriana82 was intentionally designed to be more of a social experiment, well aware that most of her audience would have eventually tried to insult her. And they did! But unlike Doretta82 (and even Tay), Doriana82 was ready to handle that.


Doriana82 answers were generated procedurally, starting from a series of regular grammars. They were selected based on a priority list. The Sunrise sort was initially used to reshuffle the ones with the same priority.
Step by Step
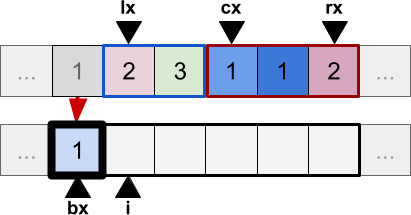
Let’s see how the Sunrise sort work, step by step. Let’s imagine that we have two parts of an existing data array that have already been sorted. Due to the way in which the Merge Sort works, they are both part of the segment contiguous segment of the original array. In the diagram below, they are highlighted in blue and red, using three indices to define the intervals: lx (left: start of first segment), cx (centre: start of second segment) and rx (right: end of second segment). The sorted elements are copied in a temp array, which is filled using an index i. The Sunrise sort introduces an additional index, bx, which represents the start of the block. For the first iteration, this is -1. The situation can be seen in the diagram below:

During the first iteration of the merging process, data[lx] and data[cx] are both compared in order to find the smallest one. Because they are equal, data[lx] is copied into the temp array first. We now have a first block, which only contains one element, and we update all indices accordingly:
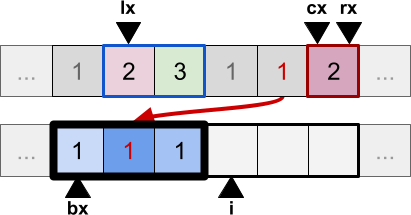
The second iteration recognises that data[cx] is smaller than the new data[lx], so the former is copied into the temp array. However, it is not just appended like it normally would in the Merge sort. Instead, it is place inside a block at a random position. In this example below, it is place after the previous value:

The process continues, and a new value is selected from the original array. Once again, this is still part of the existing block because it has the same value as the previous ones. It is then placed in a random position inside the block:
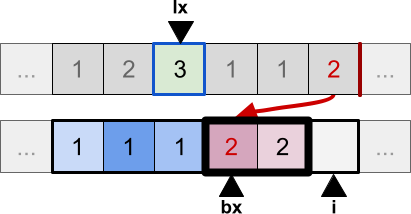
The behaviour of the algorithm changes when a new element is found, which is not part of the existing block. In that case, the block is terminated and a new one starts:

The process continues, and any element which belongs to the current block is randomly placed inside it:
Until finally, all elements have been copied to the temp array:
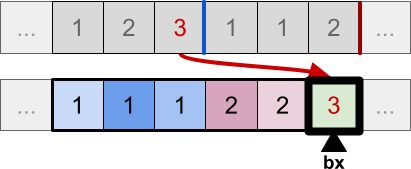
They are now all sorted, but the ones with the same values have been shuffled. The code is very efficient, as inserting a new element inside an existing block is done through swaps, without the need to actually “shift” elements (which would add a linear complexity to the operation), or to loop to identify blocks.
The Code
The Sunrise sort shares most of its code with the Merge sort. But both the merge and insertion functions are different, to accommodate for the introduction of blocks. These are the updated functions:
/// <summary>
/// Merges two sorted, consecutive segments of an array.
/// </summary>
/// <typeparam name="T">The type of the array.</typeparam>
/// <param name="data">The array to be sorted.</param>
/// <param name="temp">The temp array used for the merging.</param>
/// <param name="lx">The start index of the first segment to sort.</param>
/// <param name="cx">The start index of the second segment to sort.</param>
/// <param name="rx">The end index of the second segment to sort.</param>
private static void Merge<T>(T[] data, T[] temp, int lx, int cx, int rx)
where T : IComparable
{
int endLeft = cx - 1;
int posAux = lx;
int numElemen = rx - lx + 1;
// Block index (-1 = first iteration)
int bx = -1;
while (lx <= endLeft && cx <= rx)
if (data[lx].CompareTo(data[cx]) < 0)
bx = Insert(temp, data[lx++], bx, posAux++);
else
bx = Insert(temp, data[cx++], bx, posAux++);
while (lx <= endLeft)
bx = Insert(temp, data[lx++], bx, posAux++);
while (cx <= rx)
bx = Insert(temp, data[cx++], bx, posAux++);
for (int i = 0; i < numElemen; i++, rx--)
data[rx] = temp[rx];
}
/// <summary>
/// Inserts an element into a block.
/// </summary>
/// <typeparam name="T"></typeparam>
/// <typeparam name="T">The type of the array.</typeparam>
/// <param name="temp">The temp array used for the merging.</param>
/// <param name="item">The item to insert.</param>
/// <param name="bx">The start index of the block.</param>
/// <param name="i">The end index of the block.</param>
/// <returns>The new start index of the block.</returns>
private static int Insert<T>(T[] temp, T item, int bx, int i)
where T : IComparable
{
// The item needs to be inserted in the existing block
if (bx != -1 &&
temp[bx].CompareTo(item) == 0)
{
// Swaps
int j = Random.Range(bx, i+1);
temp[i] = temp[j];
temp[j] = item;
return bx; // Same blocks
}
// First insert, or element not part of the block
else
{
// Appends the element
temp[i] = item;
return i; // New blocks
}
}
It is easy to see that the Sunrise sort has the same computational complexity of the Merge sort: .
It is also possible to modify the Quick sort algorithm to take blocks into account. This leads to the so-called Quick Sunrise sort.
❓ Is there an alternative solution?Many languages, including C#, allow to use custom comparison functions when sorting. One might be tempted to create a fully unstable algorithm by using a custom comparator function. We could test if the elements have the same values, and if they are, randomly deciding which one is supposed to come first. Something like this:
List<T> list = new List<T>();
...
list.Sort
(
delegate(T x, T y)
{
int c = x.CompareTo(y);
if (c == 0)
return Random.Range(0f,1f) > 0.5 ? -1 : +1;
return c;
}
);
This could, in theory, work. But it breaks the contract that C# requires all comparator functions to have. If these assumptions are broken, the behaviour of many algorithms (including sorting ones) might be unreliable.
Usage & Limitations
So the question is: should I use the Sunrise sort? The answer is: probably not. That being said, it is the first sorting algorithm to be fully unstable, incorporating both sorting and shuffling into its design. With countless sorting algorithms already being used, it is unlikely that the Sunrise sort will be adopted in any real-world application. But so is the Bubble sort! Its true application is possibly in being presented as an interesting variant of a well-known algorithm. Which could be the perfect opportunity to teach sorting to Computer Science students.
The title of this article defined the Sunrise sort as a forgotten algorithm. This is because it has found its way in the list of sorting algorithms on Wikipedia for over 10 years. But due to the fact it was part of a commercial project, not many articles about it were available online. I hope this article will finally correct that, so that people working in the field will finally know more about the Sunrise sort, and its unique, quirky property.
Download C# Script
Become a Patron!You can download the full C# script to use the Sunrise sort from Patreon. The package is fully available to the public.
💖 Support this blog
This website exists thanks to the contribution of patrons on Patreon. If you think these posts have either helped or inspired you, please consider supporting this blog.
📧 Stay updated
You will be notified when a new tutorial is released!
📝 Licensing
You are free to use, adapt and build upon this tutorial for your own projects (even commercially) as long as you credit me.
You are not allowed to redistribute the content of this tutorial on other platforms, especially the parts that are only available on Patreon.
If the knowledge you have gained had a significant impact on your project, a mention in the credit would be very appreciated. ❤️🧔🏻