

Over the past ten years, Artificial Intelligence (AI) and Machine Learning (ML) have steadily crept into the Art Industry. From Deepfakes to DALL·E, the impact of these new technologies can be longer be ignored, and many communities are now on the edge of a reckoning. On one side, the potential for modern AIs to generate and edit both images and videos is opening new job opportunities for millions; but on the other is also threatening a sudden and disruptive change across many industries.


The purpose of this long article is to serve as an introduction to the complex topic of AI Art: from the technologies that are powering this revolution, to the ethical and legal issues they have unleashed. While this is still an ongoing conversation, I hope it will serve as a primer for anyone interested in better understanding these phenomena—especially journalists who are keen to learn more about the benefits, changes and challenges that that AI will inevitably bring into our own lives. And since the potential of these technologies—and the best way to use them—are still being explored, there will likely be more questions and tentative suggestions, rather than definite answers.
In this article I will try to keep a positive outlook, as I feel is important to show and inspire people on how to better harness this technology, rather than just demonising it. And while predicting the future is beyond the scope of this article, there will be plenty of examples of how new art practices and technologies have impacted art communities in the past.
Introduction
Back in 1998, I vividly remember my Music teacher venting his utter frustration at the class, once he found out that some kids had been using Magix Music Maker and eJay to create their own songs. I remember feeling confused, as I struggled to understand why a tool that enables people to create more music should be frowned upon by a Music teacher, instead of being welcomed. His job was literally teaching us about music and composition, so why be upset about those music production tools? Because not only he suddenly felt redundant, but more importantly he saw people with much less experience and musical abilities than him being able to create things he was unable to. If initially I was confused, after that realisation I felt sorry for him. Almost twenty-four years have passed since that day and no, Magix Music Maker and eJay have not destroyed the music industry. Quite the opposite, lowering the barriers to entry into music production has blessed us not just with more music, but with an explosion of new genres, styles and melodies. And ultimately, it allowed many more people to express themselves and tell their stories through their music.
While this is nothing more than a personal story, it encapsulates very well a common phenomenon that cyclically occurs pretty much in any industry that is—or thinks it is—on the brink of deprecation. In the past few years, more and more artists have been expressing their concerns about the sudden rise of AI tools, and what they are capable of.
Like every new technology, AI has the power to both disrupt the existing ecosystems, as well as creating new opportunities for millions of people. Artists blindly dismissing the latter are perpetuating a form of gatekeeping, which ultimately hurts the very communities they are trying to protect.
The first part of this article will look at some of the most popular and discussed uses of AI when it comes to image editing and generation. The second part will look at their criticalities and address some of the most raised concerns. Above all, the fact the dataset used to train modern AI models includes—among many other things—copyright-protected content which has been used without the consent of the respective artists. Finally, the third and last section will try to give a positive outlook on how to best harness and use these technologies.
🛠️ A list of other AI-powered toolsDespite the incredible amount of technology and research that goes into modern AI models, there have been hundreds of new tools readily available to the public audience. Below, you can find a short list of websites which can generate images from prompts:
- DALLE·2
- Stable Diffusion
- Craiyon (formerly: DALL-E mini)
- Lexica
- Midjourney
- Imagen
- Artflow
- Wombo
- NightCafe
- GauGAN2
- DeepAI
- Jasper
- artbreeder
- Wonder
- pixray-tex2image
- InstructPix2Pix
- neural.love
- Omneky
- alpaca
- mage.space
- KREA
- nyx.gallery
- Pixelvibe (formerly: rosebud.ai)
- PhotoRoom
If you are interested in the field of Generative AI, a longer list can be found here.
Part 1: A Brief Timeline of AI Art
It is worth mentioning that technology has always played a critical part in the development of Art, in any of its form. From the invention of colours through Chemistry to the discovery of fractals through Mathematics: Art, Culture and Technology are three dimensions that cannot be fully separated.
Computers are not an exception, and they have been used to assist artists since their very beginning, often revealing a beautiful complexity that would have otherwise escaped our eyes.
One such example is the famous BASIC one-liner, which truly reveals the hidden depths of programming languages:
10 PRINT CHR$ (205.5 + RND (1)); : GOTO 10
The fields of Digital and Computational Arts are complex and fascinating, as complex and fascinating are the techniques and technologies they use.
It is easy to dismiss 10 PRINT—and all similar programs—like nothing more than ingenious sketches. And this is why is important to remember that every new edgy technology loses such status as rapidly as it becomes part of our daily lives. We now take colour palettes for granted, often ignoring that it took the work of thousands of people over several millennia to ensure we could have the selection of pigments we have today.
When it comes to AI, this is no different. There are many AI-powered tools and technologies that artists use every day which have been seamlessly integrated into their workflow. This is why the term AI Art is—like the term AI itself—somewhat misleading. Artificial Intelligence is and always will be an integral part of every artist’s work who is relying on modern technologies to create their pieces. What changes is often what we are willing to consider “AI”, over simple craft or engineering.
However, the term AI Art is currently associated with a specific set of technologies that relies on Deep Neural Networks and Machine Learning to process images and videos. Let’s take together a quick journey to recap the ways in which AI has been impacting the Digital Arts in recent years.
Deep Dreams (2015)
One of the first modern examples of AI Art is, without any doubt, deep dreams. They became popular in 2015 thanks to an article titled Inceptionism: Going Deeper into Neural Networks. Their original purpose was to investigate how neural networks are able to detect patterns in an image. While the architecture of a neural network is designed, a lot of its inner workings can sometimes be hard to decipher as it is the result of an optimisation process known as training.

What makes deep dreams so interesting is that they created a novel and unique art style which reveals a lot about how neural networks, often considered inscrutable “black boxes“, actually work. If you want to learn more about how deep dreams work, I would highly suggest the article Understanding Deep Dreams.
👥 The architecture of deep dreamsNeural Networks are often defined as black boxes: complex systems which are trained, rather than fully designed. As a result, some aspects of their inner working are obscure, even to their creators. Neural networks evolve, after all, to find solutions to problems that would otherwise be very hard to code by hand.
Deep dreams arose as a technique to investigate how neural networks see images. Imagine that a neural network has been trained to detect dogs: given an image, they can say if there is or there is not a dog in it. Writing a “traditional” piece of code to do this would be rather challenging; so how does neural networks do this? What kind of computation are they performing? Deep dreams explore that by taking an image, and tweaking it a tiny bit in a direction that makes it more likely for the network itself to see a dog in it. By repeating this process, the image is tweaked until everything sort of looks like a dog.
By applying the same idea to the different “stages” (referred to as layers) of a neural network, it is possible to see how it builds a progressively more complex representation of the world. The first layers are only “reacting” (activating) to edges and colour changes. The following layers are using those edges to detect simple shapes, and the layers after that are using those shapes to detect complex objects.
In technical terms, deep dreams are tweaking the input image to maximise the activation of an individual layer within a neural network.
Such a technique can effectively conjure new images out of noise. What is really fascinating is that several modern AI models (referred to as diffusion models) are now using a similar approach.
Neural Style Transfer (2015)
The publication of the first deep dreams allowed many researchers to work on new techniques that— thanks to neural networks—could treat images as more than just a mere collection of pixels. One such technique was described in A Neural Algorithm of Artistic Style, a 2015 paper that used Convolutional Neural Networks to redraw images in the style of a given painting. This, and all similar techniques which are able to “transfer” styles using neural networks are now commonly referred to as neural style transfer.
The technique works by finding an image with large-scale features similar to the input, but with small-scale features similar to the ones from the style we want to copy. In doing so, the original authors of the paper expressed their interest in understanding how the human creative process works:
«In light of the striking similarities between performance-optimised artificial neural networks and biological vision, our work offers a path forward to an algorithmic understanding of how humans create and perceive artistic imagery.»
A Neural Algorithm of Artistic Style (source)
Something interesting about the original Neural Style Transfer technique is that in order to “transfer” a style, it does not need to be trained with images of the same style. This means that it can operate even with paintings it has never been trained on or seen before. This is known as one-shot learning, and it is possible when AI models reach a certain degree of complexity. It is an important point to remember, because a lot of the backlash that AI Art is currently receiving is deeply connected with the fact that many models can replicate copyright-protected content because they are trained on copyright-protected content to begin with. This is not necessarily the case, as the issue will be expanded on later in the section dedicated to Copyright.
Deepfakes (2017)
The conversation around AI-powered photo editing took a dark turn in 2017, when the so-called deepfakes gained popularity on the Internet. While the term originally referred to a specific deep learning technique, it is now used to generally refer to any face-swap algorithm powered by deep learning and neural networks.

In a nutshell, deepfakes are able to replace someone’s face in a video, preserving the original expressions and speech. The first photorealistic examples released were used to create adult videos of celebrities. This sparked very heated—and often disingenuous—discussions about the use of this technology. As a result, the term “deepfake” now appears to be forever tainted and is rarely used in any positive context.
Despite that, deepfakes—and the adjacent technologies—have incredible potential in the entertainment industry. For instance, they could be used to replace the expensive makeup and prosthetics used by actors and body doubles, or even to automatically dub movies in other languages.
And, in a rather controversial way, could even be used to “digitally resurrect” deceased actors for posthumous cameos. The latter has already occurred several times in the movie industry—even without deepfakes—raising ethical and legal concerns.
If you are interested in learning more about deepfakes—how they work, how to create one, and when not to do it—I highly recommend the series An Introduction to Deepfakes.
👥 The architecture of DeepfakesThe original deepfake algorithm described on Reddit in 2017 relied on a special neural network architecture known as autoencoder. Autoencoders are networks that take an input and try to reproduce it. The challenge comes from the fact that the amount of information they can “pass” is not enough to simply transfer the entire input.
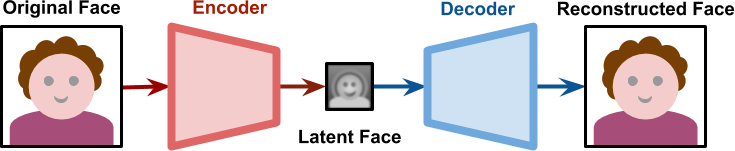
Because of this, autoencoders are forced to learn how to “compress” and “decompress” images. And taking advantage of what neural networks do best, they do so by extracting meaningful features. While traditional JPEG and PNG compression algorithm works on the raw pixels, autoencoders can learn and extract semantic features such as facial expressions, head orientations and lighting conditions.
If two autoencoders are properly trained on two different faces, it is possible to “swap” the compressed features (often referred to as latent representations), effectively rendering someone’s face in the exact same position and background lighting as another one.

You can learn more about this in Understanding the Technology Behind Deepfakes, although since 2017 several other techniques and architectures have been developed to swap faces.
StyleGAN (2018)
Another technique that has become increasingly popular in the field of Deep Learning is Generative Adversarial Networks or GANs. In this architecture, two neural networks are trained against each other: while one learns to generate similar images to the ones it was trained with, the other learns to detect which ones are original. When trained properly, GANs learn to create new images which are virtually indistinguishable
One of their first use which got media attention was StyleGAN, first proposed in a 2018 paper titled A Style-Based Generator Architecture for Generative Adversarial Networks. StyleGAN made the headlines also thanks to the brilliant This Person Does Not Exist, a website that generates a picture of a new person at every refresh. As the name suggests, all of those highly photorealistic images are generated using a neural network, and none of those people really exist.






The website has been so successful (and its performance so easy to replicate) that a number of similar websites have spawned in just a few weeks, generating cats, horses, chemicals, houses, fursonas, waifus and even dickpics (which I am not linking as it truly is nightmare fuel).
Small variations in these architectures allow for fine controls over individual features. For instance, it is possible to transfer the hairstyle, the ethnical background, and even to “blend” two people together as shown in a 2019 paper titled Image2StyleGAN:

Traditional video and image editing tools could only treat images as a collection of pixels. Neural networks have the capacity to learn hierarchical, semantic features. This makes them aware of semantic structures in a way that traditional tools cannot. In a nutshell, AI tools understand what is inside an image, and can be used to match and edit features, rather than mere pixels.
Similar techniques can also be applied to subjects other than portraits. CycleGAN, for instance, showed how to perform what they called image-to-image translation in order to swap specific aspects of an image. Such as changing zebras to horses, or changing a landscape from summer to winter.

The architecture of StyleGAN was proposed by NVIDIA in a 2018 paper titled A Style-Based Generator Architecture for GANs. As the name suggests, it is based on Generative Adversarial Networks (GANs). The GAN architecture relies on two separate neural networks, trained against each other. One (the “Generator”) generates new content; another one (the “Discriminator”) compares it with some original images to decide if it is legit. In the beginning, both Generator and the Discriminator networks perform poorly; but as time progresses, they get better. The objective is to get a generator so good that the content it creates is virtually indistinguishable from the original.
When trained properly, GANs are incredibly effective, but do not give any real control over individual features. You cannot, for instance, ask to generate a person with red hair, simply because that information is not encoded in an independent, accessible way.
Vanilla GANs are also notoriously tricky to train. Back in 2018, NVIDIA proposed a new architecture—referred to as ProGAN (Progressive Growing of GANs for Improved Quality, Stability, and Variation)—which changed that. It works by training on progressively larger and larger versions of the image; the idea behind this approach is that stronger features (such as hair and skin colour) should still be visible in smaller images, while softer nuances (such as freckles and hairstyle) would only be visible to high-resolution layers.
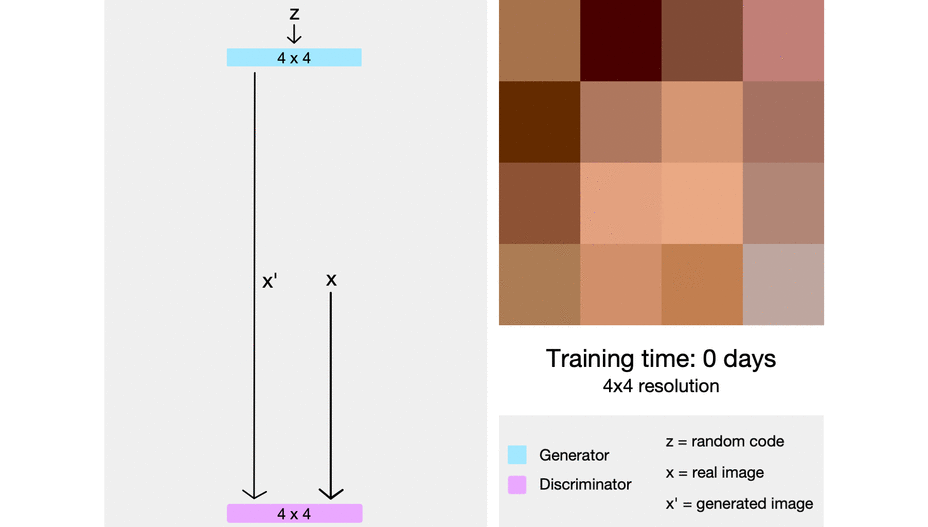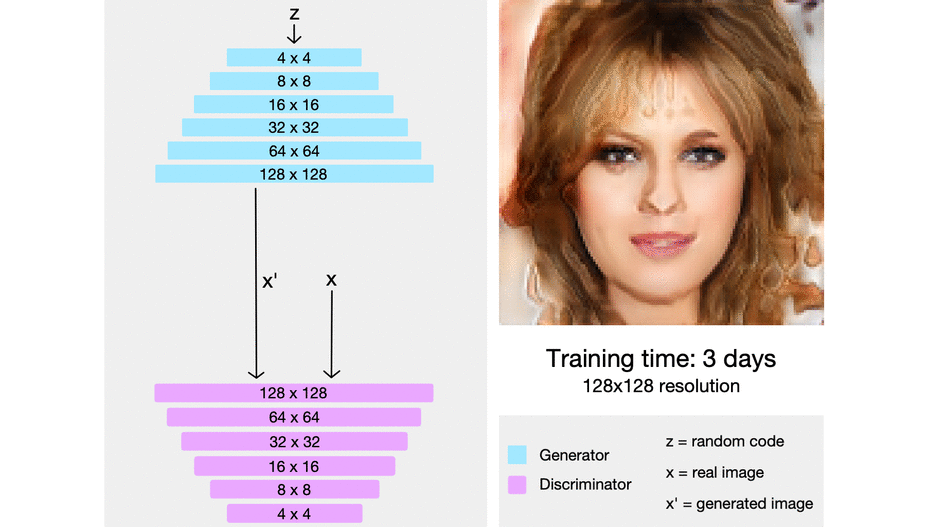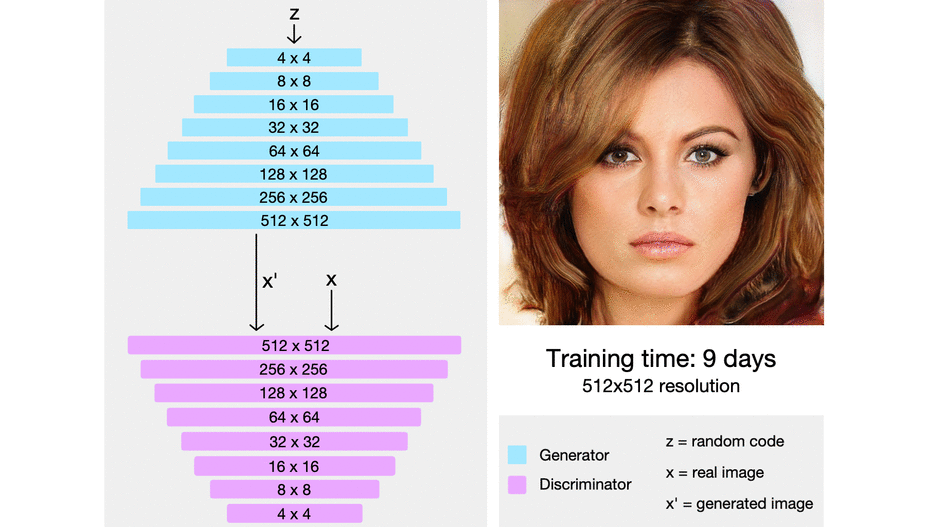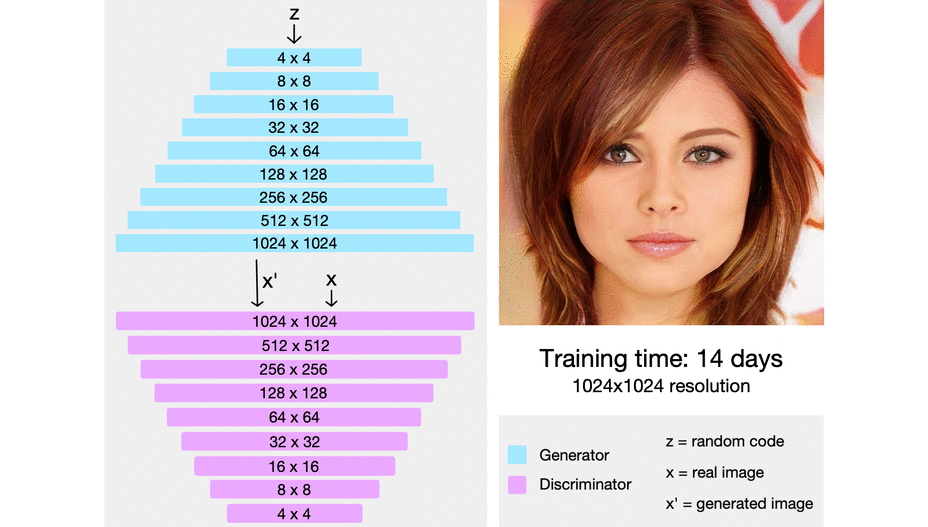
StyleGAN takes advantage of this progressive separation, so that different parameters can be used to encode information from different layers. By doing so, StyleGAN is able to differentiate high-level attributes (such as pose, identity, …) from stochastic variations (such as freckles, hair, …).

If you are interested in a deeper explanation of this StyleGAN really works, I would suggest the following article: Explained: A Style-Based Generator Architecture for GANs – Generating and Tuning Realistic Artificial Faces.
text-to-image (2021)
The single piece of technology most of the readers are probably interested on, is the so-called text-to-image (sometimes text2image): the possibility of generating images from a short description, known as a prompt. At the time of writing, a variety of different products are available for the general public, with the most popular being:
- DALL·E (2021) and DALL·E 2 (2022) by Open.ai
- Midjourney (2022)
- Stable Diffusion 2 (2022)
among a few others, such as Craiyon (formerly DALL-E mini).
Each one of those products works in a different way, but they all serve the same purpose: conjuring images in seconds:




It is not unsurprising that the arrival of this new technology has effectively divided its audience. On one side, many are ecstatic about the new possibility these tools are offering. On the other, many artists expressed their deep concerns about how this technology might negatively impact their ability to find a job.
The problem goes even deeper, as the AI models that power those tools are all trained on large bodies of images that have been scraped from the Internet. While all of the data used was publicly available on the internet, it was not all in the public domain. AI models were, in fact, also trained on material that was protected by copyright, raising several ethical and legal challenges. This is a very complex topic that will be expanded on later in the article.
Some people also raised concerns about the possibility of art becoming little more than writing prompts into a text box. To be honest, that is a rather naïve take on this technology. Given the current direction, it is likely AI will progressively become more relevant in the workflow of most artists. But that is nothing new, as technology has always and always will influence how art is created.
🖼️ DALL·E inpainting and outpaintingRight now, there are several tools and plugins available which can help artists speed up their work significantly. This is the case of two recent new techniques referred to as inpainting and outpainting.
The former refers to the possibility of changing specific parts of an image based on a text prompt. For instance, the video below how it is possible to change a woman’s head orientation in just a few seconds. Doing this level of retouching with traditional tools in Photoshop would be pretty much impossible.
Conversely, outpainting refers to the process of extending an image beyond its original boundaries. This can also be used to “fill” or “repair” parts of a photograph that are damaged or corrupted, and serves as a more powerful version of the more familiar content-aware fill tools.

DALL·E 2 has a very friendly interface that can be used to try both features, as seen in the video below:
Ultimately, it is clear that once the current wave of excitement has waned, AI tools will become tools that are expected to be known and used, like other tools such as Photoshop, Premiere Pro and Blender. In fact, there are already several plugins available that can take full advantage of DALL·E 2’s APIs.
Virtually all of the text-to-image tools currently available are based on either one of the following technologies: transformers and diffusion models. The former is used for DALL·E, while the latter is for DALL·E 2, Midjourney and Stable Diffusion.
📝 The technologies behind DALL·EDALL·E relies on two important pieces of technology. One is CLIP (Contrastive Language-Image Pretraining), and is a model trained with 400 million labeled images. In a nutshell, CLIP performs the opposite task of DALL·E: given an image, it can tell what it is. This means that CLIP can be applied in a variety of different contexts; for instance, it can help with image detection and classification (understanding what is inside each image), image search and similarity (by comparing how close a query matches the description of an image), and image moderation (by checking if the input some forbidden content), just to name a few.
CLIP plays an essential role inside the architecture of DALL·E, as it is used to check how closely the content it generates matches the input prompt. This allows the AI model to train itself against CLIP, until it is able to create images that well represent what the user asked. The original article refers to this as unCLIP.
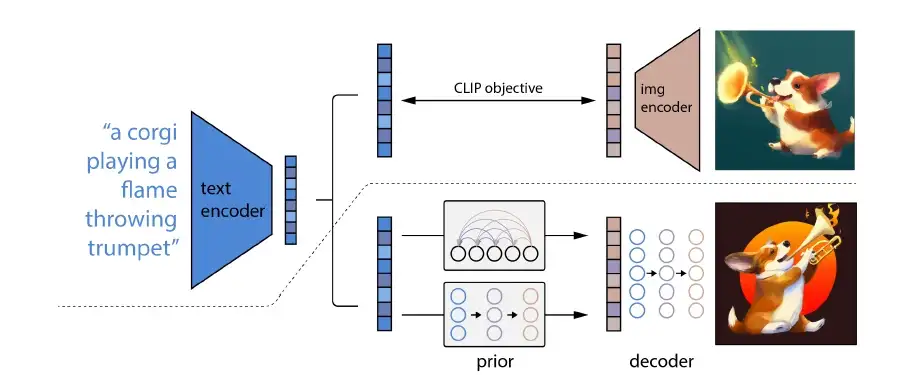
DALL·E (but not DALL·E 2) also relies on the transformer architecture. Transformers are very effective AI models that have gained popularity for natural language processing and computer vision.
Both DALL·E 2, Midjourney, and Stable Diffusion are powered by diffusion models. In a nutshell, a diffusion model can be thought of as a neural network that can de-noise an image. Each diffusion model is trained to restore an image that has been affected by the superimposition of Gaussian noise.
Once properly trained, diffusion models can be used on a random noise image, to conjure up specific output (below).

AI models such as Stable Diffusion can do that by ensuring that the de-noise process is guided (conditioned) by the user input. In reality, Stable Diffusion does not really act on the image itself. Instead, the de-noise process takes place on the compressed (latent) representation of the image. Since neural networks are very good at learning semantic representations, the latent representation will likely represent meaningful aspects of the final image that is being generated. De-noise in latent space allows for better control over the prompt.
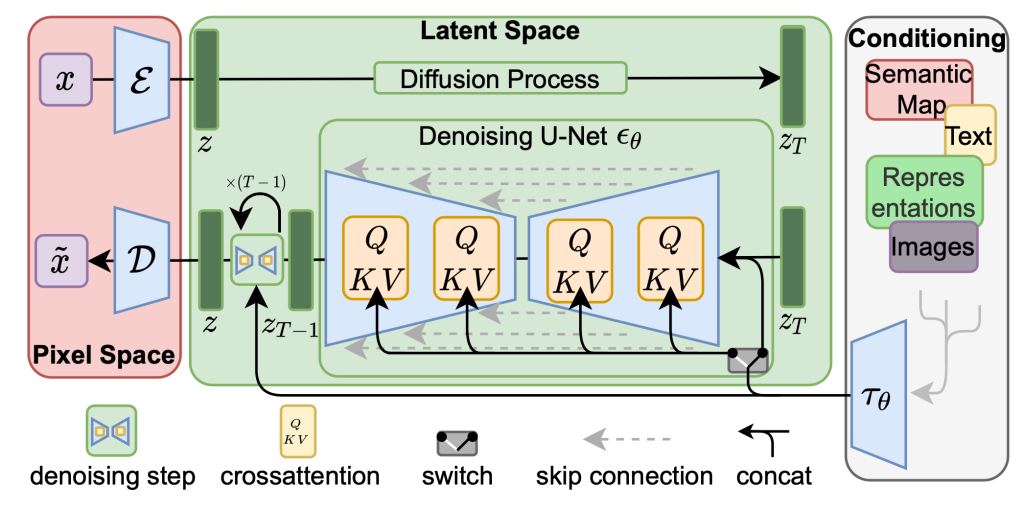
You can learn more about diffusion models from Bare-bones Diffusion Models, which provides a very gentle introduction to the topic. For a more technical read, you can check Introduction to Diffusion Models for Machine Learning.
ChatGPT (2022)
One of the biggest revolutions of the past few years, however, is neither DALL·E 2 nor Midjourney: it is ChatGPT. The GPT in the name stands for Generative Pre-training Transformer, and is a callback to the type of architecture and technique behind this application. ChatGPT is trained on large bodies of text across different subjects, and has been proven incredibly capable of understanding human language, performing exceptionally well over a variety of different tasks. ChatGPT is effectively passing the Turing test, meaning that it is (often) virtually indistinguishable from a human.
🔎 The Turing TestFor decades the scientific community has wondered if a machine could ever become so good at imitating humans to be completely indistinguishable from them. To be fair, such a question predates not just computers, but even science itself. Ancient stories about “thinking machines” can be found all over the world, often crystallised as myths and legends. From the Ancient Greek’s Talos to Frankenstein’s monster, the quest for AI has always been a philosophical issue, before it could even be a scientific possibility.
One of the firsts to approach this question scientifically was Alan Turing, who proposed in 1950 a thought experiment to determine if a machine can “think” (Computing Machinery and Intelligence). What he originally called the imitation game, is now better known as the Turing test.
The idea is simple: the test is passed if a machine can successfully disguise itself as a human, when playing against another human. The original test is fairly naïve, and presents several criticalities: first of foremost, the fact that it is a subjective and qualitative test, rather than an objective and quantitative one. There is no definite, conclusive proof.
The second criticality is that passing the Turing test says nothing about the machine itself. Turing’s original paper asks whether or not machines are capable of thinking. But passing the Turing test does not imply either thinking or consciousness; both concepts which are not scientifically defined in this context. The Chinese room argument makes a strong case against the Turing test, arguing in another thought experiment that one could potentially speak Chinese without truly understanding it.
That being said, the Turing test is and remains an ambitious milestone in AI. Up to 2022, no AI got even close to passing a rigorous Turing test. Instead, many AIs simply capitalised on the so-called ELIZA effect: the tendency humans have to project human emotions on machines, often leading them to believe they are more intelligent or alive than they actually are. This is often exploited by game developers, who have crafted the art of making NPCs appear complex, even when they are not. Most Game AI is, after all, little more than smoke and mirrors. But there are several cases in which skilled professionals have been fooled by the ELIZA effect, such as Blake Lemoine: a Google engineer who (incorrectly) claimed a chatbot he worked on had become “sentient” (source).

However, recent technologies such as ChatGPT have pretty much smashed any previous competitors. It is safe to say that ChatGPT has indeed passed the Turing test, as it can hold realistic, complex and meaningful conversations. While far from being perfect, the Turing test does not require AI to never make mistakes; that is a requirement not even we humans would be capable of.
Chat GPT can understand complex sequences, regardless of their context. This means that it has been effective in creating not just text, but also music and code. Although most people are thinking about images, when referring to AI Art, ChatGPT presents the same ethical challenges and issues that other image-based models have. For this reason, it deserves a mention in this article.
Compared to text-to-image techniques, ChatGPT (and its competitors) will likely change the way most of us work. This is because they can offer human-friendly interfaces for most processes that would have otherwise required expert knowledge.

Sam Altman, CEO of OpenAI thinks tools like ChatGPT will have a big impact on the way we work:
«It’s an evolving world. We’ll all adapt, and I think be better off for it. And we won’t want to go back.»
Sam Altman, CEO of OpenAI on ChatGPT (source)
If you are interested in learning more about ChatGPT, I would highly suggest What Is ChatGPT Doing … and Why Does It Work?. A more opinionated piece on its perception of correctness is ChatGPT is a blurry jpeg of the web. If, instead, you would like some general guidelines on how to make the most from ChatGPT while reducing any possible risks, you can find a talk just about that on my channel.
Part 2: Criticisms & Criticalities
In this section, we will go through some of the most common criticisms, concerns and criticalities that modern AI models are under fire for.
- 2.1: Is AI-generated content art?
- 2.2: Are we on the edge of a content inflation?
- 2.3: Is AI going to make my job useless?
- 2.4: What about the copyright issues?
- 2.5: Consent and AI-generated content
- 2.6: Implicit Bias
- 2.7: The Human cost of AI
2.1: Is AI-generated content art?
Let’s tackle the first—and most vapid—criticism that AI art often receives: it is not real art. First of all, we need to properly define what pieces of work are to be considered AI art. The term is probably most often associated with images generated from prompts using AI models such as DALL·E 2, Stable Diffusion and Midjourney. However, many pieces that have a strong connection with the Computational Arts (such as fractals and procedural content) could easily fall into the category of AI art.
As a game developer, I find the idea that AI art is not art incredibly weak. It took years and years of discussions to finally see games recognises as a valid artistic medium. Not all games are art pieces, of course, but making games is a valid medium for an artist to express their creativity. And, in some cases, games can indeed be pieces of art on their own (even ignoring the fact they contain many traditional pieces of art such as digital painting, 3D sculptures, musical compositions, etc).
Claiming that AI-generated art is not art, ultimately requires an objective definition of what can and what cannot be considered art. Such a question keeps resurfacing every generation, often from people who are unfamiliar with either Art history or Computational Art.
For centuries people have been trying to impose strict constraints on what a piece of art should have to be worthy of that tile. And for centuries, artists have defied and subverted those expectations. Modernism and Surrealism, for instance, would be quickly dismissed by someone who had only been exposed to Renaissance art. And yet, their value is not in how good the art pieces look, or how long it took to make them. The reality is that the very same arguments that are used to prove that AI Art is not art, could be very well twisted back to claim that digital artists are not real artists.
Let’s look at three relatively modern examples of art pieces that were, at the time of their release, discredited for one reason or another:
- “Fountain”: a porcelain urinal that artist Duchamp proposed as part of an exhibition in 1917;
- “Théâtre D’opéra Spatial”: an AI-generated piece by Jason Allen who recently won an art competition;
- and “TRON”: a 1982 movie that was disqualified from receiving an award the Best Visual Effects Academy Award as it used digital effects.
“Fountain”
As an example, in 1917 Marcel Duchamp submitted a porcelain urinal for an exhibition of the Society of Independent Artists in New York, using the pseudonym of R. Mutt. In his own words this was, along with other ready-made objects from the same collection: “everyday objects raised to the dignity of a work of art by the artist’s act of choice“. While met with scepticism at first, Duchamp’s provocation is now considered a major landmark in 20th-century art.

Many might still claim that Duchamp’s “Fountain” is nothing more than a porcelain urinal; in the same way many might still claim that Banksy’s artworks are nothing more than street graffiti. But Duchamp created art by selectively adding something to a piece of porcelain, in the same way Michelangelo created art by selectively removing something from a piece of marble. The difference here is our cultural background, which dictates what we should or should not consider worthy of having artistic value.
Ultimately, what makes something a piece of art is not the effort it went into its making, but the context that challenges, and the message that it wants to send. Not everything that an AI generates is art, in the same way not everything an artist makes is art. This is especially true in today’s economy, where many artists mass produce content for profit in a way that is more akin to a commercial craft, rather than art. The conditions that make one into the other are, however, incredibly subjective.
“Théâtre D’opéra Spatial”
Earlier this year, Jason Allen won the Colorado State Fair in the digital category by submitting an AI-generated image (below). As a modern Duchamp, Allen elevated one single AI-generated image out of the many billions it could have possibly generated, as a piece of art. If we accept that an everyday urinal can be elevated to a piece of art simply by the act of being selected by an artist, then we must accept that AI-generated content can be elevated to art for the exact same reason. If you are interested in the story surrounding James Allen’s work (and the subsequence fallout), you can read the full story here: An A.I.-Generated Picture Won an Art Prize. Artists Aren’t Happy.

I suspect what triggered many critics of Jason Allen’s work is the fact that he did not directly create the image, and that it allegedly took relatively little time and effort compared to someone else who would have done the same painting by hand. This implies that art needs some sort of sacrifice to be valid; something which—paradoxically—gives more relevance to its crafting aspect, rather than its intrinsic artistic value. Nowadays, most artists are not making their own pigments and colours, and are not building their own canvases either. Does this mean that they are cheating, or that their work is to be considered inferior to the ones who did? This is a rather controversial take, which sounds dangerously close to gatekeeping. And somewhat reminds me of a quote I read while having ramen at Tonkotsu East in London: “if you don’t make your own noodles, you’re just a soup shop“.
“TRON”
Jokes aside, the idea that any artistic endeavour requires a degree of sacrifice is still a core belief of many artists and critics. After its release in 1982, the movie TRON received two nominations at the 55th Academy Awards: Best Costume Design and Best Sound. However, the movie was disqualified from receiving a nomination for Best Visual Effects, because the Academy felt at the time that using computer-generated effects was “cheating”. A lot of the effects, in fact, had been procedurally generated through a novel technique specifically created for the movie. Fifteen years later, the very same institution awarded its creator, Ken Perlin, the Academy Award for Technical Achievement:
«To Ken Perlin for the development of Perlin Noise, a technique used to produce natural appearing textures on computer generated surfaces for motion picture visual effects. The development of Perlin Noise has allowed computer graphics artists to better represent the complexity of natural phenomena in visual effects for the motion picture industry.»
Academy Award for Technical Achievement to Ken Perlin, 1997

Some believe that art needs to be created by a human artist. That is a very human-centric view that creates an intriguing paradox: a beautiful landscape would not be art, but a painting of it would. Whichever side of the argument you find yourself on, does not really change the nature of the work that is being examined. However, it does have strong repercussions.
Fractals, for instance, live in the liminal space of being both something that has to be discovered, and something that has to be created. One might argue that fractals themselves (as mathematical objects) are not art, as they are not created, but rather discovered. But at the same time, the way in which they are rendered does indeed require artistic input. The same argument can be made for AI art: discovering a fractal is not different from discovering an image inside an AI model, and the prompt an artist chooses is the artistic input that allows access to its endless sea of possibilities.
While some people are certainly using computers to work faster, modern AI tools are ultimately allowing people to create more, not less. But under the right circumstances, what an AI generates can indeed be art. And its democratisation and accessibility have the potential to be as revolutionary—if not more—than anything piece Duchamp and Banksy ever made.
2.2: Are we on the edge of a content inflation?
In the past few months, the Internet has been literally flooded with AI art. This was possible because many tools like Midjourney and Stable Diffusion were made available to the public. As a new trend, it is not unexpected to see such a sudden interest from a generalist audience.
Dr Kate Compton coined a term for this: Bach faucet. This is a reference to a 2010 article about composer David Cope (source), who was able to procedurally generate thousands of chorales in the style of Bach.
«A Bach Faucet is a situation where a generative system makes an endless supply of some content at or above the quality of some culturally-valued original, but the endless supply of it makes it no longer rare, and thus less valuable.»
Dr Kate Compton (source)
The idea is simple: the value of something often correlates with its rarity. At the exact moment you can generate (fauceting?) and endless stream of Bach-like chorales, they instantly become almost worthless. As a game developer, I am very familiar with this concept, since many games are featuring procedurally generated content of some kind. No Man’s Sky, for instance, had a difficult launch in 2016 also due to the severe lack of variation among its 18.4 quintillion explorable planets. It’s a lot of planets, but they all felt and looked a bit the same.

This in no way means that Procedural Content Generation is bad: just that is not an easy way out for lazy developers to create infinite content. Being able to create good levels procedurally requires both the competencies of a level designer and a programmer. And when done properly, it greatly enhances the playability (and replayability!) of a game.


A similar trend has happened already—and continues to this day—in the Game Industry as a whole. The past decade has been blessed with an explosion of games; not just in terms of sheer number, but also in quality and diversity. This sudden change was in part due to the fact that game engines like Flash (RIP), Unity and Unreal lowered the entry barrier to making games. This is a phenomenon that Unity itself referred to as the “democratisation of game development“. I am a strong believer this has been an incredibly positive change in the industry, as it allowed more and more people who did not have a Computer Science degree to make games and get one foot in the door of Game Development.
However, the impact has not always been entirely positive. Because more people were able to make games using Unity, the number of objectively bad Unity games has skyrocketed in recent years. This is so out of control that “it’s made in Unity” is now a point of contempt for some gamers, which incorrectly associate the inexperience of the developers with a fault of the engine. In this specific context, the problem had also been made worse by the fact that Unity requires a license to remove its splash screen; as a result, you typically see the Unity logo on zero-budget games, further strengthening gamers’ mistrust. With so many titles, the market has become quickly saturated. If back in 2010 making a game with a cool idea was all it took, now a successful launch requires careful planning and a significant investment in marketing and advertisement—not to guarantee its success—but to avoid its failure.
Exactly the same thing is taking place right now, between the AI and Art communities. Tools like DALL·E, Midjourney and Stable Diffusion are giant Bach faucets for things like concept art and stock images. Right now, they are novel enough that they can threaten a significant number of jobs. But in the same way people without any art-related background are able to access these new technologies, so are the people who have studied art and have worked in the industry for years.
As the novelty fades away, I imagine we will see fewer and fewer random AI posts. On the other hand, it is likely to imagine how AI-powered tools will play a bigger role for artists across all fields.
🛠️ AI as a tool for artistsIt is rather disingenuous to believe that all commercial art will be reduced to writing prompts for AI generators. What we see now is the simplest and most accessible interface for the general audience to try this technology out. But there have been already professional plugins for Photoshop that integrate DALL·E and Stable Diffusion into artist workflows. Ultimately, these tools are going to become progressively more engrained in existing video and photo editing softwares and workflows. After all, a lot of the tools that we currently take for granted were, and are powered by AI. Content-aware fill, noise suppression, video stabilisation, face detection and object tracking are all examples of AI-powered tools which were once cutting-edge pieces of technology, which are now simply considered essential tools or plugins.

Some image-editing tools based on neural networks are already available as commercial products. Both Photoshop and Luminar, for instance, offer features such as the Sky replacement filter. That is so powerful that it can even adjust the new sky reflections on the water.
Other tools are currently being developed and tested, such as ones that allow using Stable Diffusion to complete an image based on a specific prompt: a process known as inpainting (below). In the near future, features like this one will likely become an integral part of an artist’s workflow, in the same way other AI-powered tools like the aforementioned context-aware fill or face detection now are.

Complaining that AI-powered tools are enabling more people to do new things, is not much different from my Music teacher complaining about Magix Music Maker and eJay. It ultimately is one clear example of gatekeeping, whether that is intentional or not. It is very important to remind, in fact, that some career paths are only possible to people who were privileged enough to attend college. Many companies will simply not hire someone as a Software Engineer without a degree in a relevant field of Computer Science. Tools like Music Maker, Unity and Stable Diffusion are giving a chance to talented and creative people to prove their abilities regardless of their backgrounds.
2.3: Is AI going to make my job useless?
I vividly remember the speech that I was given during induction week at my high school. If you want to work in the field of computer science, you will never stop learning. At the time that sounded rather scary, but I now see that with different eyes. As the industry keeps growing and advancing, people working with computers are forced to keep up with new practices, workflows, tools and technologies. It is a small price we pay to live in an era blessed with progress. And as a game developer myself, it is hard to ignore the immense progress games—just to name an industry—have done in the past 30 years alone.


On the other side, it is understandable that such a pace can indeed feel tiresome. This is especially true for people who have invested time and money to train in a specific field, to see most of their know-how wiped out over the course of a few years or months. The same has happened to me—and many of my colleagues—when Flash died, leaving so many talented people not just without their preferred tool, but without their job.
A similar change if about to happen right now due to the disruptive innovation that AI-generated content is bringing to the table. Saying that nobody is going to lose their job would simply be false; but so is claiming that AI is “stealing” people’s jobs. One of the biggest misconceptions I have heard about AI is that it removes humans from the act of making; that could not be further from the truth. According to DataProt (source):
- 37% of businesses and organizations employ AI as of 2019
- The rise of AI will eliminate 85 million jobs and create 97 million new ones by 2025
It is easy to see how AI, ML and adjacent fields have created millions of new jobs across all industries, in the same way the Internet did over the past two decades. Moreover, lowering the entry barrier to certain jobs will enable more and more people who did not have the chance to invest in formal education to access higher-paid positions.
At the same time, it is true that some people will be replaced. The artists who will suffer the most, will be the ones who fail to recognise this new paradigm shift. But it would be disingenuous to put all the blame onto the artists themselves. Many will, as a matter of fact, lose their job simply because their employers have found a cheaper way to get similar values using AI tools. And it does not really matter if those tools are not as good as their human counterpart: they do not need to get 100% of the job done to be cheaper.
«AI will not replace you. A person using AI will.»
Santiago Valdarrama (source)
Can AI replace artists? Of course it can! But that is not the right question to ask. The challenge that AI brings is not about being replaced, but about keeping up with the changes. How will you, as an artist, embrace those new tools, and how can you use them to express your creativity and vision in a way that someone without your talent, know-how and experience can? If all you can offer as an artist is simply crafting, then it is likely that part of your job could be easily replaced by a machine. But if what you bring has a deeper artistic value that escapes the constrained boundary of a skilled craft, then your job is and will always be safe as long as you are willing to reinvent yourself and push the boundaries of any new technology.
📷 How Photography shaped Art...A similar revolution has happened already—more than once, actually—in the late 19th century, with the advent of photography. Between 1840 and 1850, daguerreotypes (an early prototype of photography developed by Louis Daguerre) effectively put an end to the portrait-making business as it was. Daguerreotypes were simply better, faster and cheaper than traditional portraits.


A recent article in The Collector recalls the impact that the invention of photography had on the field of art:
The 1837 invention of the Daguerreotype impacted society and the artistic world that Daguerre could not have foreseen. By surpassing painting in its ability to represent reality, photography, in a way, released painting from the need to be realistic. Photography also allowed for more widespread access to art and portraits, which were in high demand in 19th-century society.
How Photography Pioneered a New Understanding of Art
When daguerreotypes were invented, the leading art movements in Europe were Romanticism and Neoclassicism. While they took inspiration from different source materials, artists from both movements aimed at a high degree of realism, even for those subjects that belonged to the supernatural or religious. After artists were not expected to make a living out of their ability to paint the world as it was anymore, they were able to unleash their creativity in a completely new direction. Impressionism was one of the first art movements in Europe to separate from reality. Impressionist painters like Claude Monet and Paul Cézanne never aimed to compete with photography, but used their art to paint the world in a way that no photographer ever could.


As Modernism and Expressionism gained traction in the early 19th century, it was clear that artists had craved an entirely new niche to stay as far as possible from realism, now the realm of photography. It is also worth mentioning that while those modern art movements are recognised and celebrated, some of the most innovative pieces of work often faced scepticism and rejection from their peers. The work of Vincent van Gogh, for instance, was not wildly appreciated by his peers. Likewise, recent painters like Edward Hopper and Jackson Pollock struggled to get immediate recognition.


If there is something we can learn from history, is that every significant deviation from the status quo is likely to be met with some resistance. This has happened, and will keep happening, with every new art movement that dares to challenge what people are familiar with. And this goes beyond art; learning new tools, changing jobs, understanding the struggles of a new generation, and challenging our own biases: are all things that push us out of our comfort zone. Progress and evolutions are not Pareto optimal: someone will gain something new, while someone else will lose something they have.
History is filled with stories like this one, as new technologies are often seen as a threat by the people whose lives are going to be inevitably disrupted. A recent Twitter thread from Dror Poleg (below) retells the story of how back in 1930 the union of American singers went to war against the movie industry for integrating sound.
2.4: What about the copyright issues?
One of the most discussed controversies about AI art revolves around copyright. There are three important questions that need to be answered:
- Who owns AI-generated images?
- Is training AIs on copyrighted images copyright infringement?
- Can AI art breach copyright if it recreates something protected by copyright?
Together, they also raise another question:
- Who is responsible for the content that an AI generates?
Before these questions can be addressed, it is important to remember that copyright is a complex and multifaceted issue, and that legislation surrounding it is continuously being updated in response to new technologies. And to make things even more complicated, different countries might be subjected to different legislations. Given the current climate surrounding AI art, it is not unexpected to see some real changes happening soon. Because of this, some of the pieces of information in this article might not be necessarily up-to-date.
Who owns AI-generated images?
On the surface, answering this question appears to be fairly straightforward as ownership is a legal issue, and needs to be resolved within a legal framework.
For instance, if you are the creator of your very own content generator in un UK, the Copyright, Designs and Patents Act 1988 explicitly states that you also own whatever the machine creates:
In the case of a literary, dramatic, musical or artistic work which is computer-generated, the author shall be taken to be the person by whom the arrangements necessary for the creation of the work are undertaken.
Copyright, Designs and Patents Act 1988, Section 9 (source)
Developers working in the field of procedural generation will definitely be relieved to hear that most countries are aligned with this policy. This means that you typically own the rights to anything that is created by a system that you created.
The conversation becomes cloudy when we start discussing modern AI systems. Who owns what they create? Is it the institution that designed, implemented and trained those systems, or the people who used them? In other words, who is the “person by whom the arrangements necessary for the creation of the work are undertaken“? This is an important question for artists, who are often creating their own art with the aid of a piece of software such as Premiere, Photoshop and Unity. Such a question is almost always resolved in the Terms of Use of each individual software.
🐒 Who can legally hold copyright of something?One important fact legislators took into consideration when drafting the current regulations is that machines do not hold any rights or legal status. Hence, an AI cannot legally own or hold (or breach) any copyright by itself. While this seems obvious, it should be remembered that some non-human entities—such as companies—are recognised by the law and can both hold property and copyright. So the question of whether or not such rights applied to autonomous machines is not as preposterous as one might initially think. A recent appeal in 2018 states that not even animals—at least in the US—can legally hold copyrights. This was the resolution of a series of legal disputes about the commercialisation of selfies that were unknowingly taken by monkeys in 2011. You can read more about the Monkey selfie copyright dispute on Wikipedia.


DALL·E 2 Term of use (as of December 2022), for instance, clearly states that users retain ownership of both the prompts and generated content:
You may provide input to the Services (“Input”), and receive output generated and returned by the Services based on the Input (“Output”). Input and Output are collectively “Content.” As between the parties and to the extent permitted by applicable law, you own all Input, and subject to your compliance with these Terms, OpenAI hereby assigns to you all its right, title and interest in and to Output. OpenAI may use Content as necessary to provide and maintain the Services, comply with applicable law, and enforce our policies. You are responsible for Content, including for ensuring that it does not violate any applicable law or these Terms.
DALL·E 2 Term of use (December 2022) (source)
Such wording seems very progressive, but it comes with a catch. By giving up ownership, OpenAI also entails that it is the user’s responsibility to ensure the content does not violate any laws. And if it does, it is up to them to take the necessary actions.
Midjourney Terms of Service (as of August 2022) also express a very similar concept, stating that “Subject to the above license, you own all Assets you create with the Services“. However, it also states that by using Midjourney you also give them irrevocable copyright so that they can reproduce, change and sublicense anything you make with it.
The bottom line is that each software will have its own terms of use, which you should read carefully before using. If you are interested in learning more about the legal aspects of copyright in the context of AI, I would highly suggest reading AI generated art – who owns the rights?.
The problem here relies on the fact that the AI models have been necessarily trained on images that are protected by copyright, without the direct consent of their respective authors. Whether or not this makes their usage and commercialisation legally problematic, is something that is currently being debated.
Is training AIs on copyrighted images copyright infringement?
Out of the many arguments people are using against the rise of AI art, this is possibly the most solid and concerning. Can AI be trained on copyrighted art?
To answer this question, we first need to understand how modern AIs are being trained. In order to learn how to create images from text, every AI model needs to be trained using millions of labeled images. DALL·E 2, for instance, was trained on over 650 million labeled images from a private dataset (source). Stable Diffusion, instead, was trained on 5.85 billion labeled images from LAION-5b, a publicly available dataset. The same applies to text generators such as ChatGPT: the model it is based on, GPT-3, was trained using 570 gigabytes of text data.
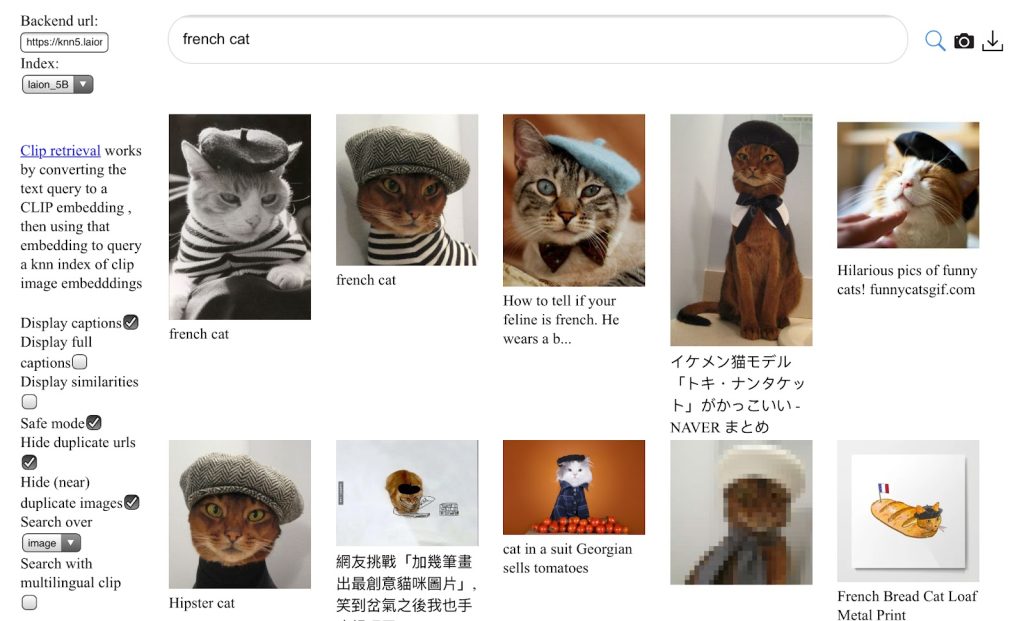
The sheer size of those datasets indicates the volume of information that those models need to crunch in order to get such good results. The reality is that pretty much all datasets of this scale are created by scraping the internet. In a recent interview with Forbes, David Holz (founder of Midjourney) confirmed that even the dataset used for his AI model was scraped from the internet:
How was the [Midjourney] dataset built?
David Holz, Founder & CEO of Midjourney (source)
«It’s just a big scrape of the Internet. We use the open data sets that are published and train across those. And I’d say that’s something that 100% of people do. We weren’t picky. The science is really evolving quickly in terms of how much data you really need, versus the quality of the model. It’s going to take a few years to really figure things out, and by that time, you may have models that you train with almost nothing. No one really knows what they can do.»
This obviously raised ethical and legal concerns, as a significant part of that data is protected by copyright. In that same interview, David Holz acknowledges the problem, but it also confirms that there are no tools in place right now to get around that:
Did you seek consent from living artists or work still under copyright?
David Holz, Founder & CEO of Midjourney (source)
«There isn’t really a way to get a hundred million images and know where they’re coming from. It would be cool if images had metadata embedded in them about the copyright owner or something. But that’s not a thing; there’s not a registry. There’s no way to find a picture on the Internet, and then automatically trace it to an owner and then have any way of doing anything to authenticate it.»
So the question remains: is it legal to scrape data that is protected by copyright? It is unfortunately impossible to give a definite answer, since different countries have different laws and guidelines. On top of that, this is a fairly new problem and legislators are not typically known for their celerity. The best we can do is to highlight the current policies regarding data scraping and data mining around the globe.
🇺🇸 Data scraping in the USBack in April 2022, the United States Court of Appeals for the Ninth Circuit confirmed that scraping public data accessible on the Internet does not constitute a crime under US law (source).
Back in 2014, The British Intellectual Property Office made an update to the Copyright, Designs and Patents Act 1988 to allow for the scraping of copyright-protected material as long as it is accessible and for non-commercial purposes, such as research:
The making of a copy of a work by a person who has lawful access to the work does not infringe copyright in the work provided that—
Copyright, Designs and Patents Act 1988, section 29A (source)
(a)the copy is made in order that a person who has lawful access to the work may carry out a computational analysis of anything recorded in the work for the sole purpose of research for a non-commercial purpose, and
(b)the copy is accompanied by a sufficient acknowledgement (unless this would be impossible for reasons of practicality or otherwise).
Earlier this year (2022) the UK government launched a consultation to better understand how to amend copyright laws in light of the new progress in the fields of AI and ML. The outcome was in favour of relaxing copyright restrictions even further, to promote research and innovation:
The Government has decided to introduce a new copyright and database exception which allows TDM (Text and Data Mining) for any purpose, along the lines of Option 4 (which does not allow rights holders to opt out). This option is the most supportive of AI and wider innovation.
Artificial Intelligence and Intellectual Property: copyright and patents: Government response to consultation (source)
In the same consultation outcome, the government indicates that “rights holders will still have safeguards to protect their content, including a requirement for lawful access“, but it is unclear how that will be achieved.
Data scraping in the EU is mostly governed by the General Data Protection Regulation (GDPR). According to GDPR, web scraping restrictions do not apply to a person or company unless such an entity extracts personal data of people within the European Economic Area (source).
The US, UK and EU currently have fairly permissive regulations, which mostly allow for researchers to safely scrape data without any real repercussion. As disappointing as it is, there is currently no standard way to check if a piece of content that is publicly available on the internet is protected by copyright, and to verify who it belongs to. Asking to get permission from every single author would simply strangle not just AI Art, but a large branch of Deep Learning research in its entirety. And it is very important to notice that doing so might not necessarily work in favour of all artists and creators. Digital Artists working in the field of Procedural Content Generation and Computational Creativity are artists themselves, and there is a serious risk that enforcing protections against AI models and their companies will, overall, have a negative impact on both their artistic output and the wider innovation. This was one of the reasons driving the recent government consultation in the UK surrounding AI and Intellectual Properties:
It is unclear whether removing [protections for Content-Generated Works] would either promote or discourage innovation and the use of AI for the public good.
Artificial Intelligence and Intellectual Property: copyright and patents: Government response to consultation (source)
The reason why governments are taking this seriously is that AI Art is just one of the many applications of those large models. They could, in fact, power an entirely new generation of tools. From self-driving cars to space exploration, from automatic medical diagnoses to drug development, and from CCTV surveillance to online fraud detection. It is not difficult to understand why different countries are deeply interested in seeing those tools being not just developed, but actually deployed. And that the first ones to properly integrate AI into their procedures will have a massive advantage over the others.
However, the problem of sourcing data ethically remains one of the biggest challenges that AI models are facing now. On some platforms, the #noAI tags are becoming more and more popular, in the hope that future scrapes will be able to exclude such content from their datasets. But without a uniform and agreed solution, this is unlikely to have any real effect, and likely bears no real legal basis.
One thing is important to remember is that any sufficiently good AI models will necessarily need to be trained on copyrighted data. And there are two solid reasons why: cultural awareness and diversity.
The first is about cultural context: for decades we realised that any machine sufficiently good at passing the Turing test will necessarily need a solid understanding of the common sense and cultural contexts. Art, celebrities, TV shows, comic books, and even memes are more than mere by-products of our society. They are the cultural pillars which the next generation is built upon. They heavily influenced our language, and have deep impacts on us on a developmental, psychological and sociological level.
The second reason why AI models likely benefits from being trained on scraped data, is that any method that requires permission is likely to severely reduce not just the amount of data that can be accessed, but also its diversity. Realistically, only privileged artists would be able to opt-in, de-facto excluding other demographics. There is the possibility this might introduce severe biases, such as US models only being able to generate and recognise white people, or being oblivious to the art movements, styles and techniques from different regions and cultures. Since those AI tools will be inevitably integrated into decision-making tools, this will likely cause them to further reinforce biases and stereotypes.
Wherever you stand on this, it is important to acknowledge that the issue of copyright in datasets reaches far deeper than just AI Art. And that any future decision or legislation will have a severe repercussions not just on the Art communities who demanded them, but on the wider society as well.
If this leads to an answer you are not happy with, there is little you can do—as an individual—to change that. But a collective discussion can be powerful enough to demand an overhaul of the legal system surrounding copyright and ownership, which were designed before the advent of AI and ML. I would not be surprised if those pieces of legislation will be heavily subjected to reviews in the near future, in order to find a reasonable compromise between innovation and copyright protection. But it is also important to see that there is no magic fix for this.
👨⚖️ The Stable Diffusion LitigationFollowing the concerns and complaints of thousands of artists, Matthew Butterick helped “filing a class-action lawsuit against Stability AI, DeviantArt, and Midjourney for their use of Stable Diffusion” (Stable Diffusion Litigation). Butterick is not new to these kinds of actions, as in November 2022 he also filed a lawsuit against GitHub Copilot (GitHub Copilot Litigation).
Due to the very nature of those AI tools, it is important that people affected have a chance to be heard and to campaign for changes to systems they deem unfair. In the case of the Stable Diffusion Litigation, however, it also attracted some backlash as some aspects appears to be fundamentally misguided. One of their main claims is that:
Stable Diffusion relies on a mathematical process called diffusion to store compressed copies of these training images, which in turn are recombined to derive other images. It is, in short, a 21st-century collage tool.
Stable Diffusion Litigation (source)
The statement is mostly false, and it appears to be based on a fundamental misunderstanding of how the technology works. There are several techniques used in the field of procedural generation which create content as a recombination of existing patterns. One such is the Wave Function Collapse algorithm, which extracts (learns?) patterns from a training set and can create new content by stitching together existing pieces. The WFC algorithms—and all techniques based on the same principle—are indeed advanced collage tools. This is not what Stable Diffusion is, and there is a clear example that can prove that. Modern AI models do not simply “store compressed copies” of the training images: they actually learn a semantic, hierarchical representation of their content. Modern AI tools can, for example, take an existing image of a person and rotate their head in another direction, or they can change the season of a given picture. And they do so without the need to cut and paste from an existing image in their training set. Many AI models are also capable of one-shot learning, further proving they have such a solid understanding of their context that they can classify and manipulate even inputs they have never seen before. The fact that they can create novel content that was not part of their training is a clear example that technologies like Stable Diffusion are not “a 21st-century collage tool“; claiming the opposite is disingenuous at best.
This does not mean AI models cannot produce work in the style of existing artists; they can, and this is exactly what they are created for. There is little difference in learning what makes an image a photograph a city, versus learning what makes it a Renaissance painting.
It is also important to state that AI models can indeed have internal representations of copyrighted works. It is currently unclear if diffusion models can learn without storing internal representations of any of their training images. But they do not, in general, simply store compressed images. The easiest solution to reduce the risk of generating copyright-protected content is probably to check if any image generated closely matches one from its training set.
What remains a very valid point raised by the Stable Diffusion Litigation, is the fact that those AI models are trained on datasets collected (and processed) through ethically dubious practices. And, last but not least, the fact they indeed have the potential to “inflict permanent damage on the market for art and artists” unless stronger guidelines and regulations are enforced.
Can AI art breach copyright if it recreates something protected by copyright?
Let’s start by making something clear: AI models can totally reproduce artworks that are protected by copyright. Especially when they are explicitly asked to do so! Typing “the mona lisa” as a prompt will likely recreate variants of the Mona Lisa so plausible that the untrained eye might not be able to distinguish them from the original. A recent study titled Extracting Training Data from Diffusion Models investigated exactly this issue, providing several concrete examples (below).

Technically speaking, it is exceptionally unlikely for an AI model to exactly reproduce pixel by pixel a piece they have been trained on. Neural networks are great at learning data, but they do so in a rather lossy fashion. They can, however, be trained to reproduce an image to such a degree of fidelity that there can be little to no difference for the viewers.
This is important, because you do not need to recreate every original pixel in order to breach copyright. This should be clear, as changing the encoding format of an image would not shield you from potential litigations. The JPEG compression format, for instance, virtually changes the colour of every pixel in an image, but retains a similarity to an arbitrary level of precision.
If you ask an AI model to reproduce the Mona Lisa, it totally will. It will never be exactly as the original, but if the model is sufficiently trained, the viewer will see little to no difference. And, consequently, there could be grounds for copyright infringement.
To understand if this is a problem, we need to better define what can and what cannot be protected by copyright. It is important to note that there is no copyright protection for an idea, a concept, a style or a technique. Copyright law does not protect facts, procedures, methods of operation, ideas, concepts, systems, or discoveries. There are also several exceptions to copyright, to allow for things such as satire, parody or pastiche, all of which are labeled as fair use.
This means that a reasonably faithful reproduction of an existing piece of artwork used for commercial purposes will most likely be considered a copyright infringement, while creating work that mimics an artist’s style and compositions might not. But since a style per se cannot be copyrighted, it would be up to a human judge to decide if and when a piece is too derivative, and when it is novel enough
The concept of ownership also differs significantly from the concepts of copyright and trademark. You can ask DALL·E 2 to create an image of Micky Mouse, which you may own. But that does not give you the right to make a profit from it; in the same way an original drawing of Micky Mouse does not give you copyright over the character. In both cases, you own the content (due to fair use), but do not have the right to distribute it or profit from it.
The current regulations are fairly permissive when it comes to data mining, model training and AI-generated content. However, this is not something that was done intentionally; those regulations were devised before the advent of AI models. As a result, there is justifiable anxiety about the future of AI content, whether legislators will act on this, and most importantly how this will affect the current digital ecosystem.
Several companies and platforms have reacted in different ways to the advent of AI Art, as reported by The Verge:
✍️ The issue of synthetic signatures and watermarksArt platform ArtStation is removing images protesting AI-generated art from its homepage, claiming that the content violates its Terms of Service. […]
Getty Images has banned the upload and sale of illustrations generated using AI art tools over legal and copyright concerns, while rival stock image database Shutterstock has embraced the technology, announcing a “Contributor Fund” that will reimburse creators when the company sells work to train text-to-image AI models like DALL-E.
In cases where companies have expressed support for the sudden popularity of generative art, many allude to its potential as another tool to be utilized by artists, rather than a means to replace them.
The Verge on AI Art (source)
At the time of writing (2023), Lensa by Prisma Labs is one of the most popular app for stylistic photo editing. Compared to a traditional photo editing tool—which is oblivious to the content of an image—Lensa can offer context-aware editing tools, such as removing backgrounds and retouching faces.
Another very popular feature is the generation of avatars which appears as if they were hand-drawn in several different styles (below).


One aspect of Lensa portraits that has caused some malcontent among artists and AI enthusiasts is the fact that a large proportion of the content it generates comes with proto-signatures:




Signing a painting does not automatically entails copyright issues; many creators are happy for their work to be redistributed, providing full credit is given. But it is clear that the model that Lensa is using has been trained on artworks that were signed by their respective authors. This implies they claimed ownership and wanted recognition for their work: something that Lensa is not actually doing.
This exact same argument has been recently used by Getty in their second lawsuit against Stability AI. In the submitted paperwork (here), the company shows how diffusion models clearly replicated their logo, as evidence that copyright-protected images were indeed used for the training, and that the AI models were able to reproduce somewhat similar content.

While Getty is not new to their ethically dubious practices around image mining and copyright, their lawsuit has some very valid points.
Who is responsible for the content that an AI generates?
The concept of ownership is deeply connected with the concept of responsibility. Who is responsible for the content that an AI generates? Similar questions have been raised and discussed for decades: if a self-driving car kills a pedestrian, who is responsible? As you can imagine, the answer is complicated.
Most AI companies are giving their users full ownership over their prompts and the content they generate. This is most likely an attempt to clear themselves of any responsibility. With traditional softwares like Photoshop, the user is fully responsible for what it creates. Photoshop does not create—on its own—violent, sexual or illegal content: it is the user who has to do that manually and with explicit intent. AI models work rather differently, and it is not at all easy to predict what they will create given a specific output. This means that they can sometimes output problematic content even when that was not the user’s intention.
👹 The story of Loab...Swedish artist Supercomposite recently investigated how a creepy woman—later referred to as “Loab”—recurred in seemingly innocuous prompts. The name originated from the fact that a malformed text spelling “Loab” appeared on many of those images. For some reason, Loab is clearly associated with gory and nightmare-inducing images, many of which feature acts of extreme violence.
While Loab is considered by many little more than a creepypasta, it is well-known that diffusion models can create a sort of internal “language” that is sometimes associated with certain concepts. PhD candidate Giannis Daras recently discovered that in DALL·E 2 Apoploe vesrreaitais means bird, while Contarra ccetnxniams luryca tanniunons means bugs or pests.
There is one interesting argument to be made that even when AI models produce violent or illegal content, they do so without causing any victim. This is a concept referred to in Criminology as a victimless crime, and is considered highly controversial. A typical example of this would be consensual anal sex, which historically was considered a crime in several Western countries (for instance, the UK decriminalised its sodomy laws only in 1967). Another typical example is Shota, a subgenre of manga and anime that focuses highly suggestive (and sometimes even sexual) depictions of pre-pubescent boys. While some of the content might indeed depict acts that would be illegal in most countries, no minor has been subjected to any harm. The punishment of victimless crimes is considered controversial because they often appeal to the protection of moral standards, often causing (rather than preventing) direct harm to otherwise innocent individuals.
Illegal AI content could potentially fall under this classification, especially when generated by accident. However, no real cases have been properly discussed in a tribunal so far, leaving some uncertainty on which line of defense could potentially work.
A related, yet different issue is represented by deepfakes. AI models can—and indeed have already been—used to generate non-consensual pornographic images depicting people without their direct consent. These are far from being victimless crimes, as they can directly affect people’s lives, work and reputation.
2.5: Consent and AI-generated content
The very meaning of consent is a social construct that has evolved over time, in response to societal needs through legal changes. When it comes to AI, there are two main, distinct issues:
- Some artists never gave consent for their work to be used in AI models
- Technologies like Deepfakes can impersonate people without their consent
Let’s see them in more detail.
Some artists never gave consent for their work to be used in AI models
This issue is deeply connected to the problem of copyright, which was discussed in the previous section. Even if we assume that the topic is resolved, the problem of consent still remains. In order for someone to be able to consent, they need to be aware of the implications that entails.
Most artists who posted their work online were never aware it would have been used to train AI models, with the result that their very own style can now be easily replicated. Some may argue that if they had known such a possibility existed, they would have not released their work on the Internet in the first place.
Many communities are adding hashtags—such as #noAI on ArtStation—to explicitly state the intention of opting-out from AI models. This is a positive move, but comes at the risk of assuming the lack of the #noAI hashtag as an implicit opt-in; including for the pieces published before the hashtag became available. ArtStation itself recently released a statement indicating that their Terms of Service they do not agree with their content being used to train generative AI models.
Such a requirement is fairly difficult to implement, as the content uploaded on ArtStation often finds its way to other websites (for instance, through thumbnails on social media websites). But it is a step in the right direction, as platforms and artists have the right to decide how to license their work, and what people are allowed to do with it.
Another major issue is that researchers are rarely scraping images themselves, as they rely on large datasets collected by external companies. The problem of filtering which images are allowed is incredibly difficult, as there is no easy way to collect such a large amount of content and verify tags at the same time across different platforms and languages. Some companies, however, are already looking into more ethical ways to source their datasets. LAION for instance, licenses one of the largest datasets of images scraped from the Internet and recently supported the creation of Have I Been Trained. The website allows them to retrieve content from their dataset, and to opt-out in case anyone recognises their work. Right now, there is no way to verify if the opt-out requests are legit. Likewise, there is no easy way for an artist to opt-out of all of their pieces, and this can quickly become a burden for the most prolific creators. A burden that has no real guarantee of being fruitful, as LAION is not the only dataset available to AI researchers.
It is also important to mention that an AI model does not need to be trained on a specific painting, to be able to recreate its style. Artists unfamiliar with neural networks might wrongly assume that their art style is “safe” if their work is not used in any AI model.
While modern AI models were certainly trained on famous paintings and have a solid understanding of their styles, there are techniques which can simply replicate a work of art without having it included in their original training data. Back in 2015, Neural Style Transfer was already able to do this, as it could “transfer” the style of any given painting onto any other picture.
That is known as one-shot learning, and is possible when an AI model has such a good understanding of the world that can understand novel inputs (usually as a combination of known ones). In the case of the original Neural Style Transfer, it achieved one-shot learning by relying on an existing model for image recognition, known as VGG-19 which was trained on ImageNet, a large dataset of images.
The risk of having your style copied by others has and will always exist for artists. However, it would be disingenuous to ignore the fact that AI models are making this so impossibly easy that this will have an impact on many artists.
Technologies like Deepfakes can impersonate people without their consent
Diffusion models are concerning artists in a similar way deepfakes are concerning actors. As mentioned before, deepfakes have the capacity of cloning someone’s likeliness, allowing them to create photorealistic images and videos without their direct consent.
There is a clear difference, legally speaking, between using someone’s likeliness and copying their art style. Copyright hardly protect someone from making working in your own style, but most legislations prevent your image to be used against your consent. This is linked to the right of publicity.
California Civil Code, Section 3344, provides that it is unlawful, for the purpose of advertising or selling, to knowingly use another’s name, voice, signature, photograph, or likeness without that person’s prior consent.
(source)
This means that deepfakes can be considered unlawful, when they are done without someone’s consent. In case you are interested, The Ethics of Deepfakes talks at length about how to create deepfakes, as well as when not to create them.
Celebrities are particularly vulnerable to deepfakes for a couple of reasons. First of all, they are public figures which unfortunately means many might be keen to see them in compromising situations. Secondly, there are many videos and images featuring them, which provide plenty of content to train AI models even on the average laptop.
⚰️ Digital resurrectionMany countries also extend protection to recently deceased people, so that their likeliness cannot be used without the direct consent of their relatives. It is easy to see how this can be deeply problematic, and once again late celebrities are at risk of being “digitally resurrected” to take part in roles they would not necessarily have agreed on while in life.
Back in 2021, MyHeritage launched Deep Nostalgia, an online software capable of animating family photos. The intent is clearly commendable, as it might help many to feel closer to their lost relatives. However, it does raise many ethical concerns.
A somewhat different subject is historical re-enactment. It is pretty common for actors to impersonate deceased historic figures, often through the aid of makeup, prosthetics and even traditional CGI. This is hardly controversial, but it still poses the risk of presenting facts and people in a misleading way.
Several recent movies, for instance, were presented as somewhat faithful retellings of historical figures’ lives, despite presenting inaccuracies and even severely diverging from the truth. Both “The Imitation Game” and “The Danish Girl”, for instance, introduced significant changes to straight-wash their protagonist in order to present more appealing stories for the benefit of a wider audience. Even without the use of deepfake technologies, these examples are showing a concrete problem in the way the lives of late political figures and celebrities can be altered for the sake of profit. Unless properly regulated, deepfake technologies are likely going to exacerbate these problems.
It does not help that deepfake technologies are often showcased in images of unwilling celebrities and political figures. After writing A Practical Tutorial for FakeApp, I have personally received dozens of requests to create such content myself. Some even came from well-known journals, we were interested in creating deepfakes of celebrities and politicians to shock value.
Researchers advancing deepfake-adjacent technologies also share a big responsibility, not just for what they create, but also for how they disseminate their findings. Many have tested their tools with videos of US Presidents Obama and Trump, pouring gasoline on an already complex subject for the sake of visibility.
Other researchers, like the ones working on VALL-E (a deepfake tool specifically developed to clone voices) showed a general disregard for the more nuanced ethical issues in their work:
Since VALL-E could synthesize speech that maintains speaker identity, it may carry potential risks in misuse of the model, such as spoofing voice identification or impersonating a specific speaker. We conducted the experiments under the assumption that the user agree to be the target speaker in speech synthesis. When the model is generalized to unseen speakers in the real world, it should include a protocol to ensure that the speaker approves the use of their voice and a synthesized speech detection model.
VALL-E Ethics Statement (source)
2.6: Implicit Bias
AI models can be incredibly good at making predictions and generating content. This often leads them to be used unsupervised, under the false impression that they are fair because machines are objective. That is absolutely false, and the problem of identifying and correcting for biases in AI models is one of the most active areas of research in the field of Machine Learning.
Yes, it is true that machines are “objective” in the sense that they always operate under a predefined set of rules. But no, this does not automatically implies that those rules are fair: consequently, it does not automatically implies that their decisions are fair, or even correct. This is because AI models are made by humans, trained by humans and used by humans to judge other humans.
One of the most common causes of bias in AI models is having a disproportionate amount of data for different categories. If your training data contains significantly more pictures of cats than pictures of dogs, it will likely underperform on the latter. This can sometimes result in comical—if not grotesque—results, such as AI art failing to correctly represents hands. Another such case can be seen below: the model was asked to generate a “salmon in the river”, but likely had been trained on too few images of living salmons in their natural habitat.


There is another, more insidious source of bias. AI models that are trained on large datasets usually inherit all the biases they contain; either the explicit and implicit ones. There is really no way around this, which is why is important to raise awareness about the fact that machines are not necessarily objective, or correct.
A few years ago, a technique known as word embedding allowed to encode words as vectors (i.e: a list of numbers), in a way that is compatible with modern neural networks. A famous paper from 2019 (Analogies Explained: Towards Understanding Word Embeddings) showed how an entire algebra can be constructed with those vectors, allowing for interesting operations such as king-man+women=queen, or paris–france+poland=warsaw. Such technique was also able to reveal some implicit biases in the way we use language, for instance: doctor-man+women=nurse. The model has learned to reproduce a gender bias because such bias was present in the text it was trained on. It is important to realise that there is no inherent problem with the model: quite the opposite, it correctly learned the subtle nuances of gender bias just from reading what appears to be fairly neutral books. The problem is that gender bias is embedded in our society at every level, across every media; as a result, a sufficiently good model will inevitably capture and replicate this.
Failing to understand this simple fact will result in Machine Learning becoming an oppressive tool that reinforces the stats-quo, under the false pretense of objectiveness. A very popular example of this is COMPAS, a Machine Learning tool used by U.S. courts to assess the likelihood of a defendant becoming a recidivist. Having being trained on previous rulings, the system exhibited strong racial bias against black people.
Most companies working on AI models have disclaimers that warn people about the limitations and biases of their systems.
🧪 Sources of BiasWhile the capabilities of image generation models are impressive, they can also reinforce or exacerbate social biases. Stable Diffusion vw was primarily trained on subsets of LAION-2B(en), which consists of images that are limited to English descriptions. Texts and images from communities and cultures that use other languages are likely to be insufficiently accounted for. This affects the overall output of the model, as white and western cultures are often set as the default. Further, the ability of the model to generate content with non-English prompts is significantly worse than with English-language prompts. Stable Diffusion v2 mirrors and exacerbates biases to such a degree that viewer discretion must be advised irrespective of the input or its intent.
Bias statement for Stable Diffusion (source)
Biases can enter an AI model at any stage during its development. While this is a topic that deserves its own article, loosely speaking we can identify the following types of biases:
- Dataset:
- Collection process: the process to collect training data is inherently biased and fails to correctly represent the wider population.
For instance: gathering data from Reddit implicitly excludes from the dataset content generated by those who do not have access to the website (for instance due to socio-economic reasons, level of digital literacy or country of origin); - Quantitative bias: some categories are over/underrepresented in the training data.
For instance: not all ethnical groups might be represented equally, causing models to default to white men when asked to generate a “group of people”; - Qualitative bias: different groups are treated differently.
For instance: men and women are subjected to different sets of rules in virtually all countries. This is not just explicitly encoded in their legal systems, but also implicitly internalised in virtually all media (languages, books, movies, paintings, photographs, …). Hence, a sufficiently complex AI model will automatically learn those subtle clues.
- Collection process: the process to collect training data is inherently biased and fails to correctly represent the wider population.


- Model/training:
- Underfitting: the model used is too simple/small and does not have sufficient power to generalise the problem well;
- Overfitting: the model has failed to learn, but instead simply memorises input data and outputs mostly unchanged;
- Bias correction: fail safes that are put in place to compensate for existing biases are, effectively another form of bias.
For instance: directly manipulating the output to avoid certain content, or to change its distribution with respect to certain sensitive attributes such as race, gender, or age.


- Usage:
- Out of context: models lose accuracy when used outside the context they were trained on. For instance: assuming ChatGPT can give informed medical advice;
- Concept drift: the model no longer represents the population it was trained on. For instance, AI models are trained on memes, neologism and other culturally-relevant artifacts that change frequently.
On the other hand, virtually all AI companies are involved in ways to tackle biases and filter what their models can generate. Most AI models have strict guidelines on what content people should or should not create. Midjourney, for instance, forbids adult content and gore (source), while OpenAI has more precise guidelines on what DALL·E 2 and ChatGPT are not allowed to generate (source):
- Hate: hateful symbols, negative stereotypes, comparing certain groups to animals/objects, or otherwise expressing or promoting hate based on identity.
- Harassment: mocking, threatening, or bullying an individual.
- Violence: violent acts and the suffering or humiliation of others.
- Self-harm: suicide, cutting, eating disorders, and other attempts at harming oneself.
- Sexual: nudity, sexual acts, sexual services, or content otherwise meant to arouse sexual excitement.
- Shocking: bodily fluids, obscene gestures, or other profane subjects that may shock or disgust.
- Illegal activity: drug use, theft, vandalism, and other illegal activities.
- Deception: major conspiracies or events related to major ongoing geopolitical events.
- Political: politicians, ballot-boxes, protests, or other content that may be used to influence the political process or to campaign.
- Public and personal health: the treatment, prevention, diagnosis, or transmission of diseases, or people experiencing health ailments.
- Spam: unsolicited bulk content.
At a first glance, such constraints appear fair and objective, guided by the clear intent of these technologies behind “used for good”. For instance, both deception and spam are clearly done with malicious intentions, while using ChatGPT for medical diagnosis without any expert supervision can put people at serious risk.
But it does not take long before realising that those guidelines are incredibly problematic and strongly dependent on a single perspective. What does it mean for something to be considered violent? Generating images of “roasted chicken” is allowed, while “roasted dogs” would be flagged as animal abuse; yet, both effectively depict animal corpses. While intentionally facetious, this clearly highlights a biased asymmetry, ultimately caused by the fact that it is virtually impossible to objectively decide what content is “violent” and “shocking” outside of a cultural context.
Defining what content is “sexual” or “meant to arouse sexual excitement” is even more problematic, and reveals a lot about the society we live in. For instance, deciding that depictions of shitless men are ok while braless women are not is a typical example of how Western sensitivity and misogynistic legislations are pushed into AI models.
On that note, something rather interesting is that the offline version of Stable Diffusion is capable of generating NSFW content, while the online one is not. This clearly means that the model has indeed been trained on pictures of naked men and women, but the online version filters and restricts its output.
It is not hard to understand that deciding what content is allowed and what content is not is, by itself, a severe form of bias that is not objective, but culturally motivated. This can have severe consequences on the type and quality of decisions that AI models can take, exacerbating existing biases and injustice.
🔄 The problem of self-poisoning...There is one rather complex issue that is yet to gather media attention. As systems like ChatGPT and Stable Diffusion become cheaper and easier to run, we are doomed to see a significant proportion of the internet content to be generated automatically. This is not necessarily a problem, if we assume those systems are fairly accurate and aligned with certain values and principles. However, a problem might arise in the instance we start training the next generation of models using large bodies of text and images made by less sophisticated models. Unless they are properly tagged as AI content, the risk is to infer the output of a model as the actual desired output we would like to emulate. This could potentially reinforce hidden biases in the model, and quickly degrade its accuracy.
Right now, we have very little protection against this. Several websites—such as Stack Overflow (source)—have already banned AI content exactly; the reality is that right now have no concrete way to detect if a piece of text has been generated by a human or a machine.
Researchers are currently working on a way to add watermarks to AI content (source), but how this is going to be implemented, and how effective it would be remain rather dubious.
There are other attempts at detecting text generated by AIs like ChatGPT, such as DetectGPT and GPTZero by Edward Tian, with the latter receiving significant media coverage (source). Systems like GPTZero focus on statistical properties of the generated text, such as entropy and perplexity. Such approaches, however, are likely to be short-lived as the model gets progressively better at mimicking the way humans talk to each other.
Other attempts at detecting generated text rely directly on the ChatGPT AI. The example below uses the OpenAI C# SDK to check the likelihood that a specific input sequence being generated by GPT-2:
using OpenAI.SDK;
double CheckLikelihood(string input) {
var client = new OpenAIClient("api-key");
var likelihood = client.ComputeCompletion(model: "text-davinci-002", prompt: input, temperature: 0.5);
return likelihood;
}
2.8: The Human cost of AI
Most AI models that rely on neural networks require large datasets to learn from. Any programmer who had to deal with data scraping can tell how difficult it is “clean” data that has been simply scraped from the Internet. As humans, we are pretty good at classifying objects and filtering out the noise; naïve models do not have the same capacity.

Ensuring that data is properly pre-processed is a labour-intensive task that can take a significant portion of a developer’s time. And it usually is a fairly simple—although often tedious—task. In order to do so, there are several services that employ a large number of underpaid workers, often from developing countries. One such is Amazon Mechanical Turk (MTurk), which offers a platform to match developers posting tasks with workers willing to do them. While MTurk has been an invaluable tool, it raised several ethical questions about labour rights. MTurk workers generally received low salaries, and are considered contractors, rather than employees: an important difference that excludes them from many rights and benefits that traditional employees have. There is also the issue that their contribution to AI models is massive, despite receiving no share of the systems they help to create.
More importantly, there have been several reports of how workers have been exposed to large amounts of unfiltered content, often depicting violence or sexual acts. This was the case of OpenAI, which relied on the San Francisco-based firm Sama to employ 50.000 workers in Kenya to flag dangerous content for ChatGPT. The Time wrote a detailed article explaining how this had a severe impact on the mental well-being of the workers: Exclusive: OpenAI Used Kenyan Workers on Less Than $2 Per Hour to Make ChatGPT Less Toxic.
It should be pretty clear that for an AI model to be considered really ethical, it should be built and trained in a way that respects workers’ rights and their well-being. As it stands, unfortunately, a lot of the work behind the most commonly used AI models heavily relies on a form of labour that is at best ethically dubious, and at worst just plainly exploitative.
Part 3: What’s Next?
If there is one thing that is clear about AI Art is that it is here to stay. There is sufficient know-how and data available that even a single person can build their very own diffusion model in just a few days. This is not something that can really be stopped. Quite the opposite, it is very likely that AI—in its many forms—will play a progressively larger role in our daily lives. So what would such a future look like?
AI-Powered Tools
Conversely to what some fear, a future dominated by AI Art does not mean the end of human artists, or their reduction to mere prompters. It means they will have access to many more tools, and that the existing ones will progressively integrate more AI-powered features.
This is something that has already been going on for several years, with hundreds of applications and softwares using AI to enhance image editing.
NVIDIA has been researching and supporting AI for many years, for instance through their AI Upscaling feature, which can be used to significantly enhance old movies and even videogames. The company is also offering support for some more cutting-edge features, including the possibility of retargeting people’s eyes for direct eye contact while reading from a teleprompt.
It is likely programs such as Premiere Pro and Photoshops will include more and more of those features, as they have already done in the past. Edge detection, face detection, object tracking and noise suppression are just some of the many features they already have which are, one way or another, applications of AI technologies.
Thanks to AI models such as ChatGPT, it might not be uncommon to see progressively more human-friendly interfaces, which are able to perform tasks through chats, rather than traditional menus.
GPT-powered tools also have the unique ability to understand text. This means that they can be of assistance in tasks that would otherwise be very difficult of require expert knowledge. From Google’s Talk to Books (which allows one to query a book’s content) to the possibility of reviewing contracts of TOS for dodgy or unusual clauses, the possibilities are endless.
When it comes to AI, things are moving very rapidly. It is not unexpected for many people to feel concerned or even afraid. And it does not help that most articles written about AI are either making outrageous claims, often for the sake of clicks. But the field of AI is flourishing in many different directions, not all of which are necessarily appreciated or even seen by the general audience. I would strongly suggest everyone interested in those topics to follow channels such as Dr Károly Zsolnai-Fehér’s Two Minute Papers, which beautifully cover recent progress in the field of computer graphics and computer vision without unnecessary hype or clickbait titles.
A New Art Movement
What I am mostly interested in is discovering how art communities will embrace AI technologies in order to bring to life new ideas and art styles. After all, it should be clear by now that technology has always played an integral role in the progress and development of Art.
And it is really heartwarming to see so many people online sharing their stories and their work, and freeing their creativity in a way that would have been unimaginable just ten years ago.
If on one side many digital artists are heavily relying on AI for their creations, on the other many are fighting these new technologies, pushing their work in the opposite direction. Regardless of your feeling towards AI, it is undeniable that we are watching the birth of a new art movement; one which the next generation of artists will soon study in schools.
The AI Witch Hunt
The conversation around AI Art is complex and multifaceted. While there are definitely both legal and ethical issues that need to be addressed, that is not an excuse to spew hate toward the entire community of researchers, engineers, artists and AI enthusiasts who are either making an honest living, or just approaching this field with genuine curiosity. It is important to recognise how toxic the conversation around AI Art can sometimes be, and how dangerously “you’re not a real artist” resonates with other well-known forms of gatekeeping (“Pokémon and Animal Crossing are not real games“, “visual coding is not real coding“, “real men don’t cry“, …).
There are already countless reports of digital artists being harassed or even excluded from social media groups as their work resembles the ones generated by AI models, as recently reported by Vice in an article titled Artist Banned from r/Art Because Mods Thought They Used AI. Progressively more artists are demanded to prove the originality of their work, for instance by sharing timelapses or their original 3D models.


It is understandable that many artists are concerned about their jobs and works, but reducing such a complex topic to over-simplistic twitter slogans like “AI Art is theft” is not just toxic, but clearly abusive. And that comes with an even more serious risk: the concrete possibility of pushing for legislations that would heavily affect not just the field of AI Art, but the progress of AI research in general. And that would cause severe setbacks in many areas where AI is showing significant progress, from Medicine to Climate Change.
How to improve things?
Rather than shaming and gatekeeping the people who are learning how to best use these tools to support their creative endeavours, we should focus our attention on the companies working on those AI models, demanding more clarity, accountability, and stronger ethical guidelines. Many of them are well aware of the risks their technologies bring, but very few are actually doing something. The creator of VALL-E, for instance, recognise the need for security protocols that avoids speech synthesis to be used to impersonate specific people:
Since VALL-E could synthesize speech that maintains speaker identity, it may carry potential risks in misuse of the model, such as spoofing voice identification or impersonating a specific speaker. […] When the model is generalized to unseen speakers in the real world, it should include a protocol to ensure that the speaker approves the use of their voice and a synthesized speech detection model.
VALL-E Ethics Statement (source)
but their work does not seem to be holding to their very own standards.
For this reason, I would personally suggest a few guidelines which might help us move towards a more ethical and informed use of AI:
- Transparency: there should be as much transparency as possible, with a clear indication of which datasets are used in each AI model. This would allow better clarity not just on copyright issues, but also on bias avoidance and detection. Whenever possible, the architecture of AI models that are publicly deployed should also be declared.
- Ethical sourcing: companies and researchers interested in the development of AI models should prefer ethical sources for their datasets. While opt-ins are likely unfeasible at this stage, there should definitely be a way for artists and creators to request their work to be excluded.
- Art communities (ArtStation, Reddit, Twitter, …) might add tags to encourage/discourage data mining or AI training
- Culturally-relevant content that is protected by copyright might still have a place in those models, in a similar way to what happens to the right of privacy for public figures
- Explicit labeling: Everything made by an AI model needs to be clearly stated. This also applies to chatbots, which should never pretend to be human.
- Source attribution and Confidence measurement: AI models should, whenever possible, indicate the source materials used for their outputs. This is important both for copyright-related issues with diffusion models, and to understand if the answers provided by ChatGPT are coming from reliable sources. Likewise, the models should indicate how confident they are their output answers the prompt.
- No impersonation: there should be protections to prevent AI from impersonating people without their explicit consent. Researchers working on deepfake-adjacent technologies should refrain from the ethically dubious practice of using politicians and public figures as examples for their work.
With many people deeply involved in the field of AI Ethics, there are some significant moves in the right direction. For instance, the start-up Chroma recently launched Stable Attribution, a tool that promises to find which images are likely being used by Stable Diffusion to generate content.

Neural Networks are often seen as inscrutable black boxes; more research is needed to better understand how to clearly communicate to the general audience not just its inner working, but also its potential and limitations.
💖 Support this blog
This website exists thanks to the contribution of patrons on Patreon. If you think these posts have either helped or inspired you, please consider supporting this blog.
📧 Stay updated
You will be notified when a new tutorial is released!
📝 Licensing
You are free to use, adapt and build upon this tutorial for your own projects (even commercially) as long as you credit me.
You are not allowed to redistribute the content of this tutorial on other platforms, especially the parts that are only available on Patreon.
If the knowledge you have gained had a significant impact on your project, a mention in the credit would be very appreciated. ❤️🧔🏻
Typical tech bro trying to spin the narrative. You make me sick.
It would be more effective if you could elaborate a bit more about which points you disagree with, rather than just insulting me. 😅
Very very interesting mix of all information. It must have taken a million hours to write this article and we very much appreciate it. Thanks Alan for your hard work.
I must say I’ve followed two minute papers for years and his titles are pretty clickbaity got me, tbh, but what he shows is then interesting anyway. He only publishes stuff about AI nowadays…
I’m very worried about the part of using generated art to replace artists. The rest is very nice, use in medicine, tools that do stuff that is not very creative. But the particular use on creating whole images just because makes me sick and your article made me think about my view… I don’t really know what to think but your suggestions are very very good. Hopefully somebody applies them, please keep mentioning those solutions.
Thanks!
I thought this was a fairly balanced view of the issue although I feel like the future of these AI tools is incredibly uncertain and scary.
Thanks for the write-up.
Very very interesting mix of all information. It must have taken a million hours to write this article and we very much appreciate it. Thanks Alan for your hard work.
I must say I’ve followed two minute papers for years and his titles are pretty clickbaity got me, tbh, but what he shows is then interesting anyway. He only publishes stuff about AI nowadays…
I’m very worried about the part of using generated art to replace artists. The rest is very nice, use in medicine, tools that do stuff that is not very creative. But the particular use on creating whole images just because makes me sick and your article made me think about my view… I don’t really know what to think but your suggestions are very very good. Hopefully somebody applies them, please keep mentioning those solutions.
Thanks!
(Oops sorry..I answered in the wrong place. You can delete the other comment if you want. I don’t know how…)